

The S Curve Strikes Back
Riding the Singularity's Second Differential

Last week, we put out a piece called "The S Curve is Here," arguing that fundamental constraints on scaling - specifically energy use - would eventually put the brakes on the AI hype cycle.
The thesis was simple: yes, if scaling continues, machines will continue to get more intelligent. But there's a catch. The rate at which those machines become more intelligent per unit of energy/cost has fundamentally peaked. Not in total, mind you, or over 100 yrs, but locally - insofar as the jump between GPT 3 and GPT 4 was likely the single most dramatic shift in the technology ecosystem since the iPhone.


In that piece, we tried to estimate how much total energy and compute it would take to get the 'error' rate (the distance between what the robot says and what a 'good' outcome looks like) down to various thresholds. The math was brutal - to get a loss of 0.1 would require 1,000,000,000,000,000,000,000x global energy production, just to feed the GPUs. To get a loss of 0.8 you would need 50bn GPUs and all of world energy. Stuff like that.
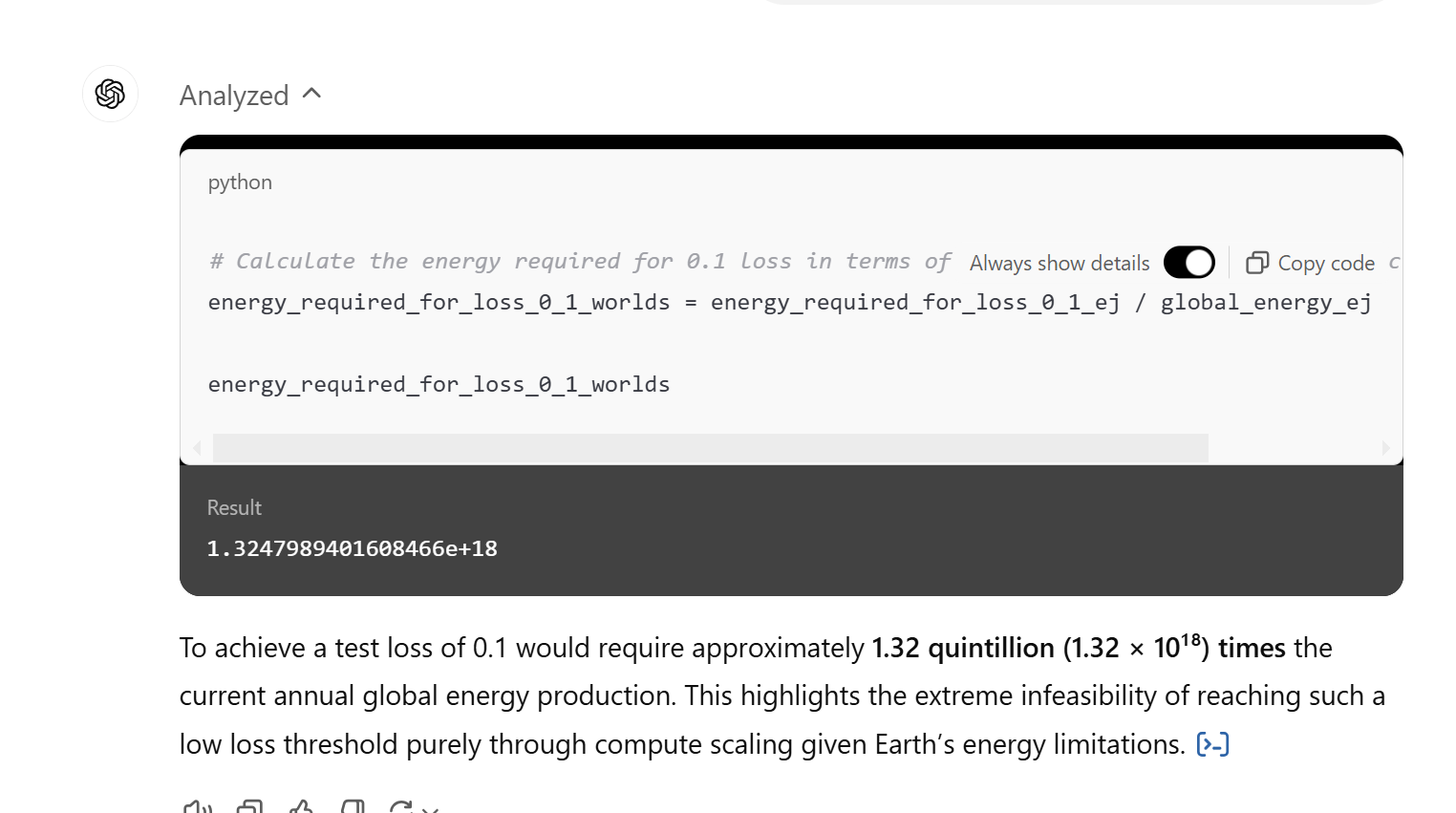
It was a theoretical exercise that pointed to a practical truth: there ought to be a point at which the marginal return to scaling decreases. Scaling can hold, conceptually there is a point where the economic return to doing so is negative…at least for now, in this S curve, represented by what they call ‘pre-training.’
Aka the world can only support so many GPUs chugging away at matrix math before we start having to make uncomfortable tradeoffs, like whether we want AGI or agriculture.
Then on Friday, OpenAI dropped o3. Take that, S curve.
First, the good news: this thing is a beast. It shocked the world by demonstrating capabilities that blew past previous benchmarks, particularly in domains like mathematics and coding.

We're talking about performance that puts it within striking distance of being the 'best coder' ever.

Which, when put on a timeseries, makes a mean exponential!

Now for the reality check: each question costs about $3,000 in compute to answer.

Not cents or dollars like previous models - thousands. Think about that for a minute. The marginal cost of o3 thinking about a problem is roughly equivalent to a week of a junior developer's salary.

Which is where things get interesting for our S-curve thesis. Yes, it's awesome that we now have machines that can one-shot previously impossible questions. But the question of ubiquity - when these capabilities become widely deployable - remains firmly tied to economics.

Let alone whether, as we continue to bang on about, there's enough silver out there to actually feed robots which need $3k of energy per question...

This disconnect between capability and practicality is where I see a lot of the doomers getting high on their own supply. It comes from a particular lived experience and thought pattern common among a certain type of knowledge worker.

Let me explain. There's a natural tendency among junior analysts or junior devs to think about their work as highly transactional:
"I submit the deck during the partner dinner, they look at it and give red comments before heading home, then turn the comments (1-5x), finalize the pdf, and get it to the printer. It has to be on everyone's desk bound by 7:15 am tomorrow morning."
Or:
"The product manager provides me the specs, design collateral, and requirements. I go to github and fork the main repo, branching into my local. Then I draft, implement and test my solution. Submitting it as a 'pull request' to production."
When your mental model of work is just the ingestion, prioritization, processing, creation, and distribution of various digital objects - files, code, charts, tables, pdfs - the job begins to feel automatic and machine-like. Something that could (and should) be automated. In fact, this line of thinking was partly why I left NYC tradfi for Silicon Valley startups - the idea that the rise of intelligent machines would radically transform how we do "knowledge work."
Now we have evidence that for one of those steps - the pure thinking part - the machines are indeed more capable. You can absolutely imagine contexts where a $3k answer is worth the price tag. Think billion-dollar investment decisions, critical policy choices, or anything requiring rare expertise.
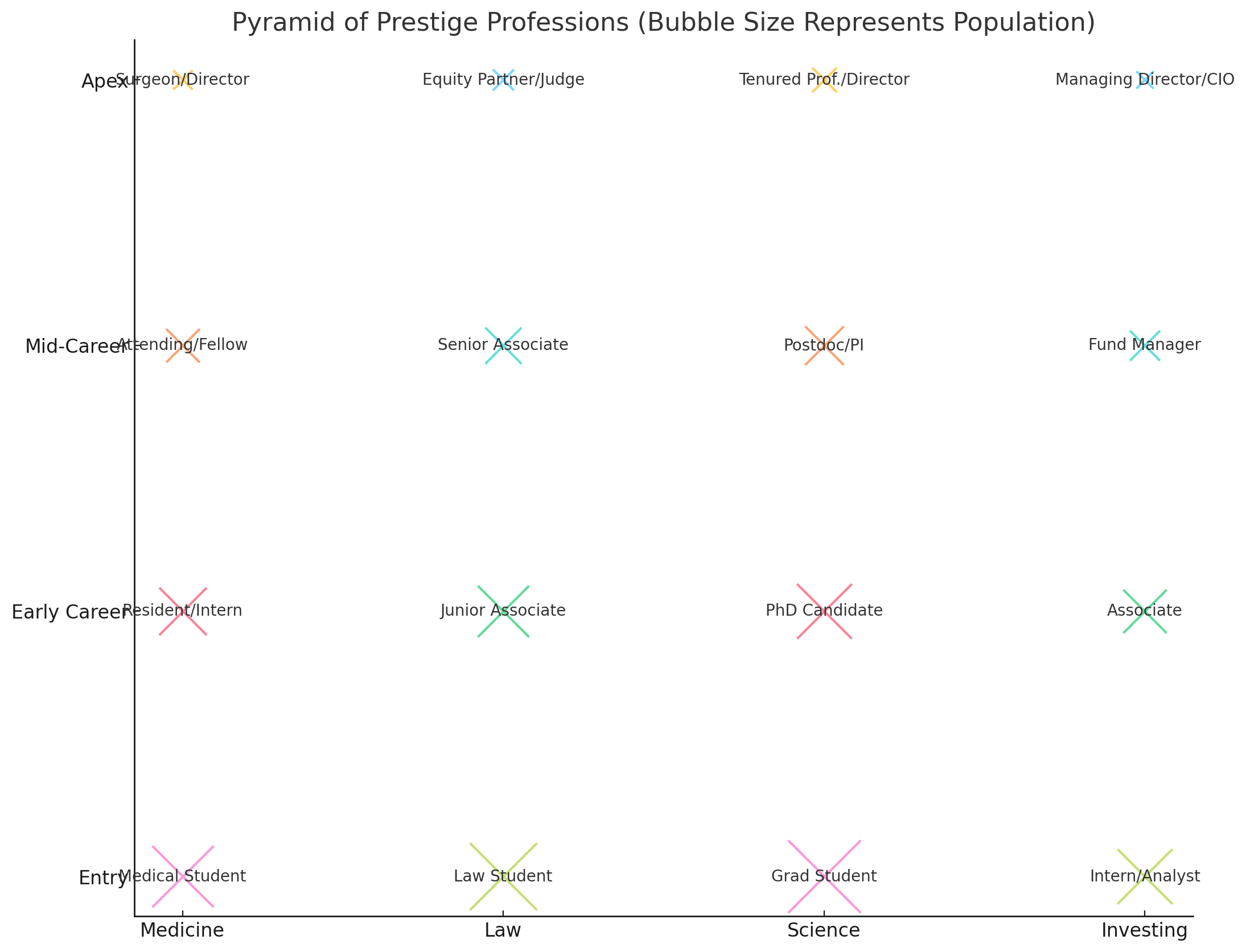
Look at how this maps onto any professional hierarchy - medicine, law, finance, tech. You've got this beautiful pyramid structure:

But here's the thing about o3 that perfectly illustrates our S-curve thesis: getting that capability required phenomenal amounts of compute. The total cost to run the ARC-AGI benchmark was around $1.6 million - more than the prize they were competing for. This is exactly the kind of diminishing returns we predicted.

The practical implications show up in the development process itself. That bubble above? It took probably 20 prompts of back and forth between me and the robot to get it halfway decent. Each iteration taking 15-45 seconds, each potentially costing serious compute. Even a machine 'smarter than me' isn't able to 'see' certain things that would be obvious to a human - like overlapping text or basic aesthetic balance.
This hints at a deeper truth about these systems: at $3k a correction, your robot needs to know so much stuff to either a) never be wrong, or b) quickly correct course when it is. There's nothing worse than a machine that takes forever to halt. So imagine the frustration of working with a 'superintelligent' robot that needs 50 minutes to reply and lots of expensive course correction.
Regular readers will recall our piece on "Don't Trust Machines" - where we argued that some problems simply don't have correct answers. Turns out, what we were really seeing was a practical manifestation of what Turing called the Halting Problem.

A quick look at one of the problems that o3 (high) got wrong emphasizes how easy it is for machines not only to hallucinate but fail to see something that might be obvious to a trained human:

Look at those examples - the machine can't even consistently recognize the simple pattern of connecting blue dots, despite being "smarter than me" on paper. Why? Because just like every other machine we've encountered, from the NYSE matching engine to your local bank's ATM, these things break in predictable, cascading ways. What Turing figured out mathematically, we're now experiencing practically: there's no such thing as a perfect machine.
Which brings us back to the fundamental point: yes, o3 represents a dramatic step forward in raw capabilities. But the economics of deployment (via the petering out of the pre-training S curve) mean we're still a ways from general replacement of knowledge workers. By our count, given recent trends in the price of compute + efficiency, that $3k/question won't become competitive with human labor (which handles ~20k+ cognitive tasks a year) until 2029/2030.

Which is consistent with what the bond market is telling us - yields selling off despite all this talk of AI-driven productivity growth. The market doesn't believe we're about to see an immediate productivity miracle. What it does see is the massive investment needed in energy and compute infrastructure to make any of this real, and some consumer tech companies that look capable of the scale required to build and tune these machines.
In the meantime, this release actually reinforces our core thesis: that progress in AI will increasingly be constrained by energy, compute and data costs, leading to diminishing returns on raw scaling from ‘pre-training’. The future isn't about who can build the biggest model - it's about who can build the most efficient one, and who can build the energy and data pipes needed to feed them.
Though speaking of control, while we are here on the dawn of AGI, three bright lines we should probably draw:
Machines cannot own property (the incentives matter)
Machines cannot convict people of crimes (the loops problem is real)
Machines cannot operate with deadly force (latency kills, literally)
These principles are, ironically, already being violated in various ways. Which is a story for another ramble.
Till then.

Interesting article published at 9:56 PM on Sunday night... got anything better for 2:37 am?
Meanwhile, I’ll enjoy my cognitive tasks being worth $60 million/year in AI land!