

The Routing Problem
Why GPT-5's "Smart Router" Reveals Something Deeper About AI

As discussed yesterday, the release of GPT-5 raised some important questions about the nature of exponentials. In particular, the exponential increases in intelligence versus the exponential increases in the inputs to training and running those models: as these models get exponentially more capable, they also get exponentially more expensive.

The problem initially looks like one with a practical solution: not all questions—even within a single conversation—require mega-models to answer.
GPT-5 attempts to address this problem (and the implicit cost tradeoff baked into it) via a “router” which decides in the moment whether a big model or small model should handle your query.
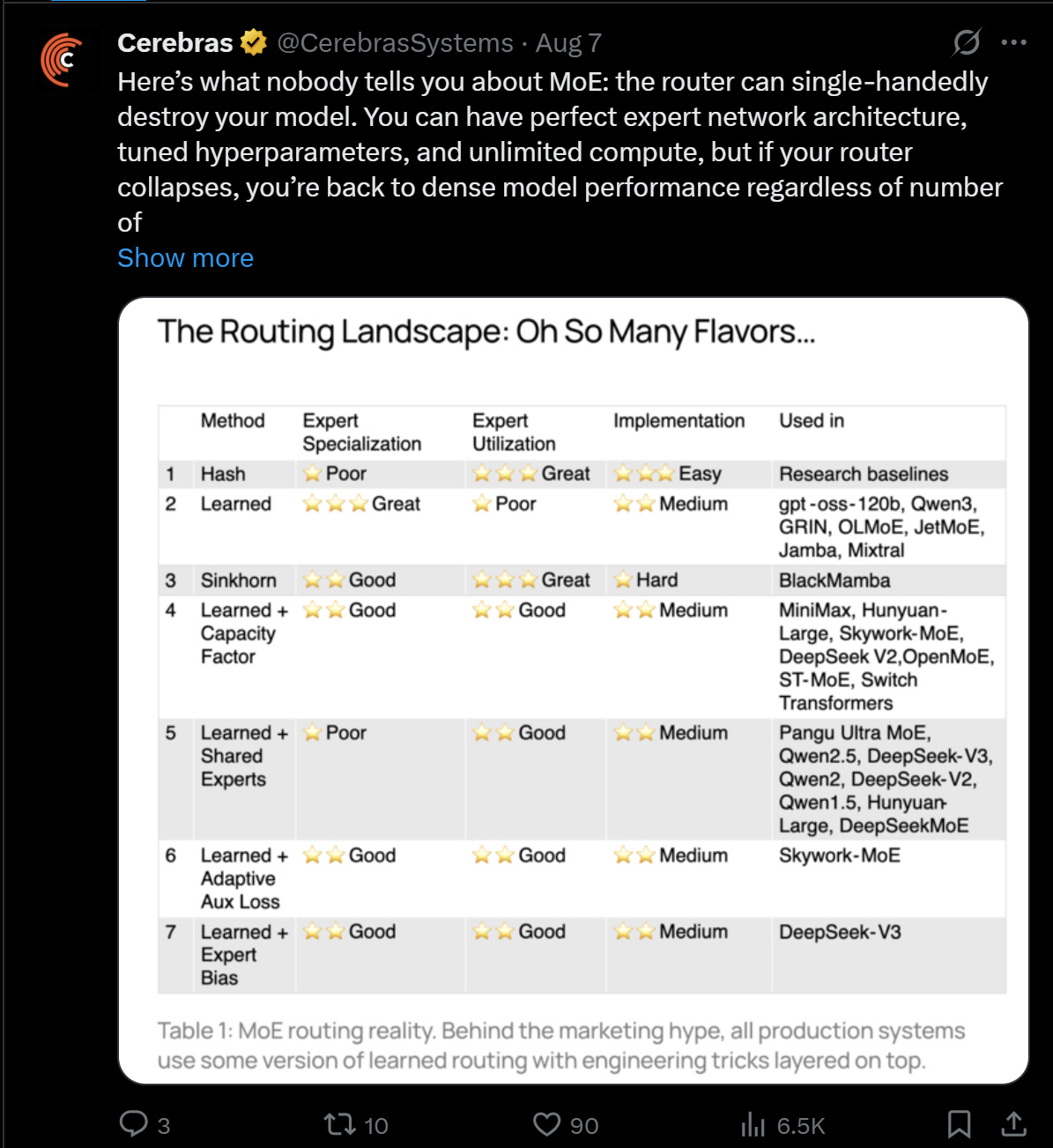
It's a natural extension of the Mixture of Experts ("MoE") paradigm popularized by DeepSeek, where instead of one monolithic gigantic model, you train many smaller ones (say 2 billion parameters versus 200 or 2 trillion) and a gating or function decides which expert in your mega-model answers your particular question. This takes that idea and then classifies your prompt by what kind of model they think best answers it.
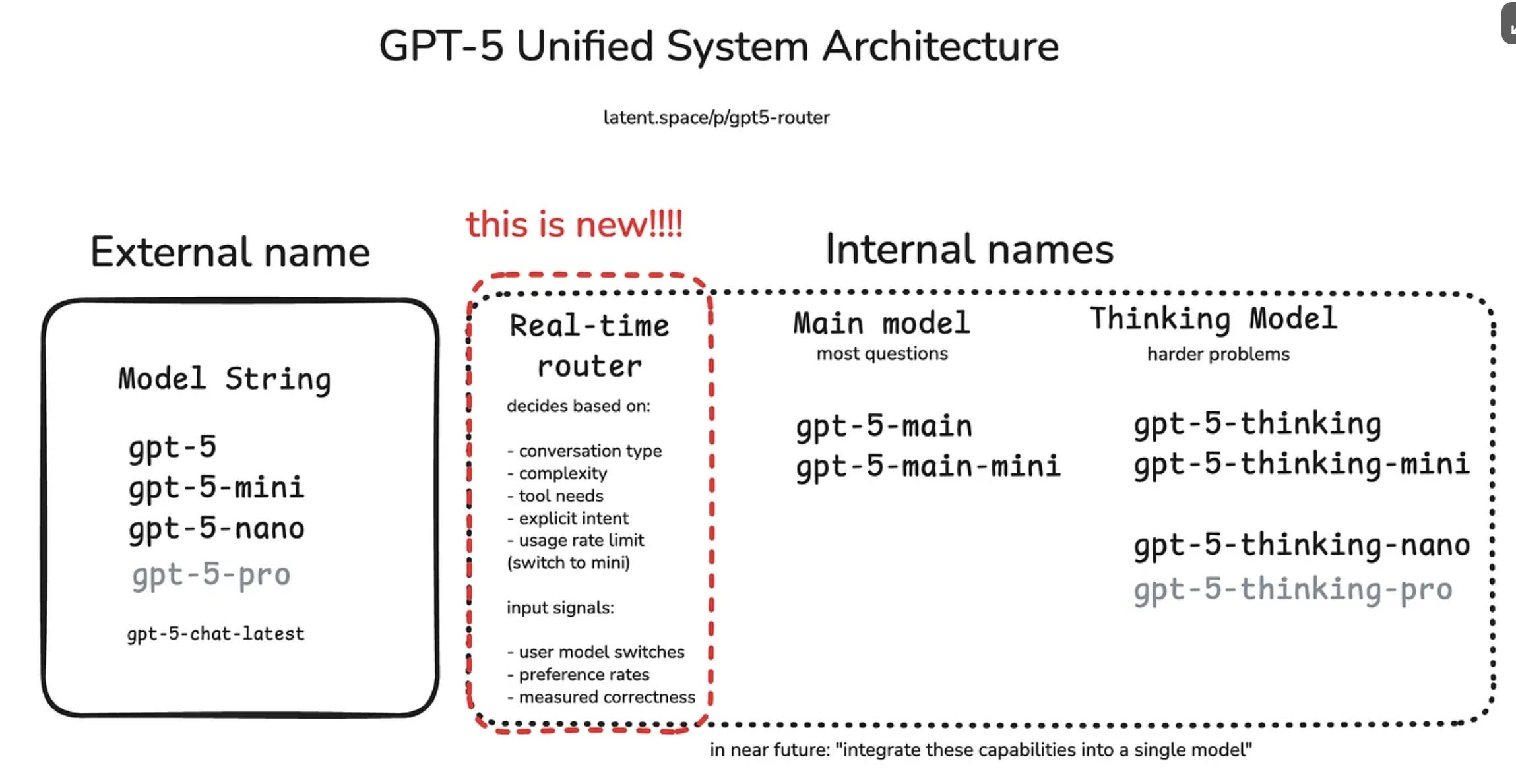
It also happens to minimize coasts, by only using big models when necessary.
On paper, this is a good idea. Obviously influenced by our obsession with benchmarks and the whole automation training pipeline optimization problem.
Problem is, real world conversations are not just evaluation datasets with neat sets of questions of specific degrees of difficulty. Real world fluid intelligence is messy—going back and forth over easy questions, hard questions, things that require written responses versus visual ones.
You see this even in the models' difficulty interpreting whether you want them to draw something versus write something. I've found GPT-5 trying to use code to generate a visualization when answering a question that's clearly a request to just draw the damn thing.
This is not an easy problem.
The Paradox at the Heart of Routing
The problem of routing is conceptually difficult because there's a paradox baked right into it.
Let's say you simplify the world down to easy questions and hard questions.
Hard questions require big (read expensive and slow) models to provide satisfactory answers, and easy questions can be dealt with by small (read cheap and fast) models.
As a well-meaning technological capitalist, you decide that rather than use the big model on everything—which guarantees good answers but costs a lot of money and takes a prohibitive amount of time on trivial questions—it makes sense to 'route' the responses to your questions.
Problem being, this then begs a meta question: "Is this question hard or easy?"
Which often is a harder question than the original question itself!
Sometimes prioritization is inherently more difficult than answering the specific query.
This is familiar to anyone who's managed smart kids fresh out of school—lots of book smarts, no street smarts. They'll often return a simple off-the-cuff answer to your difficult, nuanced question, completely missing the inherent complexity of what you've asked them. Conversely (and especially after some reinforcement learning on this first issue), they'll also overcomplicate answers and kick off massive research projects for what are seemingly simple tasks that could be knocked out in less than an hour.
As my old boss Greg Jensen used to say: "I just wanted a chart. I don't want you to cure cancer."
The Computational Existential Crisis
To be clear, this problem is not intractable. It's difficult. But in that difficulty lies the same kind of computational existential ambiguity you get in things like the halting problem, Gödel's incompleteness, Russell's paradox, Heisenberg's uncertainty principle.

The notion that the very act of formalizing a problem is itself a simplification of the very messy, chaotic, and uncertain real world. In this formalization, you necessarily clip the rough edges of reality to fit into your framework, your model, your machine. And in these cases, those rough edges inevitably "break the machine"—or as we say, "the machine is down."
Leading to the conclusion: don't trust machines.

This isn't to say we don't use machines. But we should always have a healthy respect for the isomorphic dissonance between the logic inherent in machines and the chaotic, messy reality of real-world problems.
What This Means for Jobs
This connects to something deeper about what's special about humanity and what's necessary about humans—what we might call "jobs." As we've written before, we have machines that automate farming work like tilling, reaping and threshing and yet we still have farmers. We have robots that automate TCP/IP and yet we still have technicians and engineers who work on and fix those systems when they go down.

If you look at the heart of the most complex and critical manufacturing processes in the world—the semiconductor fabs creating the chips that power the machine intelligence revolution—you have extraordinarily carefully controlled environments, built and maintained by humans.
Makes you wonder: when will there be no more jobs? Maybe when we have fully automated semiconductor manufacturing plants. Doesn't seem like something we'll hit by the timelines espoused in doomer docs like "AI 2027." But even then, there'll probably be another layer of complexity for humans to build, maintain, and deal with when things break.

The routing problem isn't just a technical challenge. It's a window into the fundamental gaps between elegant machine logic and beautiful human chaos. And in those gaps—what I like to call the spaces where "the machine is down"—lives something irreplaceably human.
Disclaimers
Beautifully written and thoughtful.
Also if anyone ever says the works "maximizes my comprehension/sec" in real life I will absolutely punch them in the face for no reason other than the betterment of the universe.
this auto-routing vs Hierarchical Reasoning Model? Frankly, I am not expert and not sure if it's more relevant to deployed model efficiency per unit of intelligence AND/OR a faster RL w/ algo-Abstraction embedded. (the obvious con is that it's "just" sudoku and mazes, but that would be a bit US/Mag7 biased/vested considering how quickly it learns vs SOTA).
https://www.sapient.inc/blog/5