

What if AI weren't inevitable?
September 29th, 2016


Among certain folks, it’s become fashionable to state that (true) AI is inevitable.
I disagree.
Yes, exponential increases in data and processing cycles have unlocked solutions to lots of problems that, until now, were pretty hard for humans…
Chess! Jeopardy! Go! Chatbots! Identifying Pictures of Cats!
But, we know these solutions don’t represent general intelligence, because there are also lots of examples of machines getting into pretty big trouble with relatively simple problems (more on these examples later).
And, there’s actually a pattern in the type of problems machines succeed vs the one’s where they tend to fail.
The machine fails when we fail.
In particular, when we fail to understand, structure and represent reality in the machine.
Meaning the “problem of AI” is not a quantitative question of X terabytes of data + Y computation cycles, but a qualitative question.
Maybe in order to create a machine that thinks, we need to understand what thinking really is.
Maybe to understand what thinking really is, we need to understand what it means to be human.
And maybe, just maybe, we never answer that question.
Which, after all, would be kind of ok.

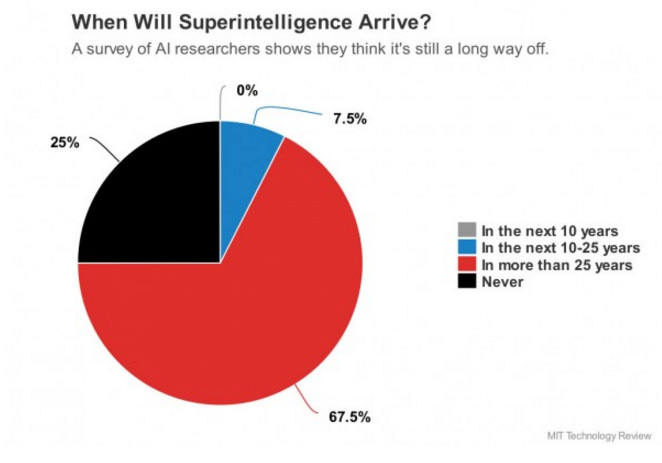
The Consensus
For many people, the question has no longer become IF we will ever be capable of designing and implementing machines that are capable of human level intelligence, but WHEN.

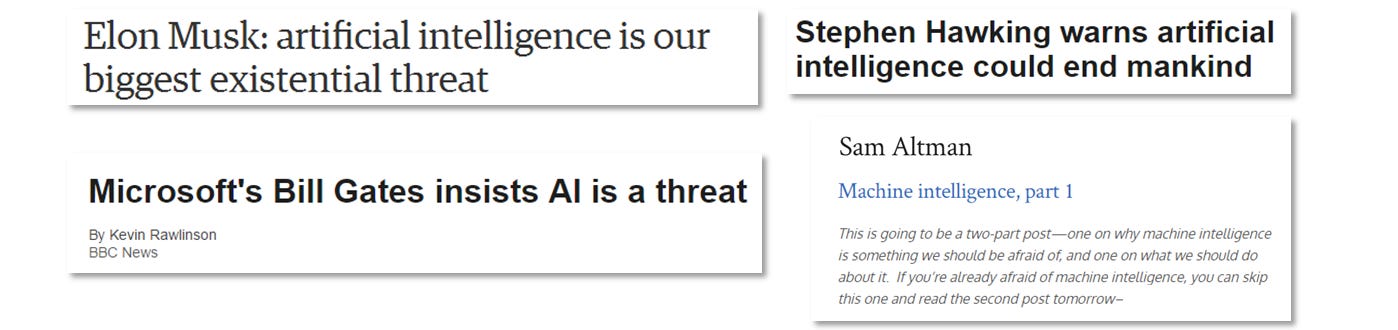
It’s not just Oxford dons that are convinced. Titans of industry are sounding the alarm…
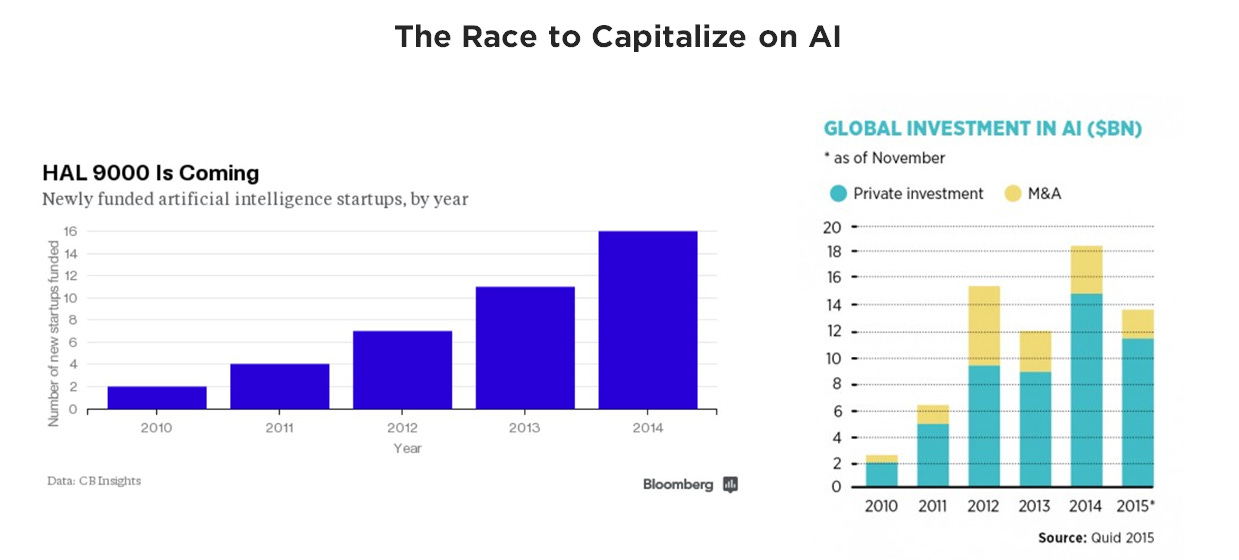
Capital, as it is want to do, is in hot pursuit of monetizing technological consensus..
Which brings us to today.
The Problem is Us
warning: a bit geeky
Here is some state of the art work on machine learning. The guy sucks in a ton of faces to an algorithm, which then generates plausible human faces.

This pretty cool.
What’s interesting here (at least to me) is not only how good the algorithm is, but where it fails.
Try telling the machine to rotate the face, and it falls apart.

Which, when you think about it, is kind of the same problem that this guy found when looking at image classifiers.
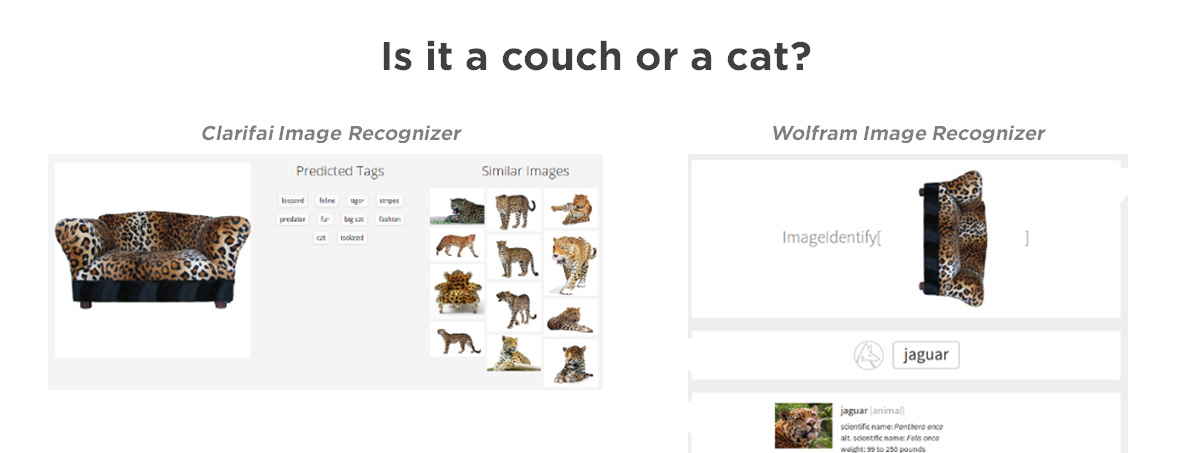
To me these examples kind of proove that it’s not so much a matter of quantity of information or data, but the quality of the representation of reality within the machine.
The structure.
In the first example, the question is — can we have a robust generative model of faces without the machine having an explicit representation of three dimensional space?
In short, doesn’t the machine have to “understand” spacial dimensions in order to “understand” faces?
That seems like a problem that is another order of complexity more difficult than generating faces that look like blends of the other faces in the database.
Hacking together a better model (with a Kinect and more data), might solve the rotation problem, but that’s kinds of the point. Not HOW the model is wrong by but WHY.
Meaning, the problem of getting a machine to “understand faces” is less limited by data and computation, and more our ability to provide an accurate, comprehensive, robust representation of reality *in a machine*…meaning, we may be overconfident about how close we are to artificial general intelligence
In the second example — the machine doesn’t really have a representation of ‘furniture’ vs ‘stuff that’s alive’, which means it draws a simple inference (by pattern matching to the data it has been exposed to) which says anything with that pattern is a specific type of cat.
All which proves (at least to me) that it’s not just a matter of incremental improvements in a) computation cycles and b) data.
Meaning there’s a third constraint (outside of cycles and data), and it’s…*us*
These aren’t examples of machines failing, they are examples of our inability to understand the nature of the world, structure that into a functional representation, and implement that representation in a machine.
Which seems more an existential problem (at least at the moment!) than something we can write off to incremental change. At the very least, it’s something which should give us pause.
Or put another way:
