

The Race is On
Going Deep on DeepSeek and the Dawn of Distributed AI
Remember when they told us China was going to “pause” AI?
If you want a preview of the take, look no further than Twitter/X:

I remember, because I was there, in the trenches. Fighting the good fight (against SB1047). Getting called stupid for daring to question them.

Regular readers of the blog know this has been a hobby horse of mine for the last couple of years, not just the lack of logic behind this view (it’s irrational, literally), the lack of empathy (wouldn’t you?) but the lack of respect it belied (“they can’t catch up with us.”). Never short China’s ability to see an idea and build a better version for 8x cheaper…
Well, last week a little know quant shop called DeepSeek shocked the silicon valley grand poohbahs by dropping a model which competes with the big boys not only in terms of capacity, but scares them in terms of how efficient it was to train. Some of the poohbahs are so shocked, they have even resorted to casting aspersions.

So today, we’re going to break this problem into a couple of sections. In the first section we’re going to talk about the backdrop to this conversation, starting with the folks that up till this week, felt secure lecturing the world on China’s inability or unwillingness to compete at the bleeding edge of the most critical technology of a generation.
Second we’re going to go hands on, and tell you what we think they actually did, how they made it so efficient, what is does well (math) vs poorly (speed) and what markers of this process you can see looking in the code, and talking to the bot.
Finally, we’ll lay out some potential conclusions at the intersection of scaling, alignment, open source, and, yes, the inevitable (and to a large degree welcome!) competition that just now feels like has truly begun. Personally, we’re excited that Jevons is all of a sudden being in vogue (after appearing in our pitch deck for the better part of a year), and even more excited about what happens when people start applying it to the data part of the scaling problem, not just the hardware!
Doomers Delight
Time to eat crow doomers. For those of you coming to this for the first time, recall as soon as ~four months ago, the argument from AI doomers on a unilateral move to slowing and potential pause AI development was thus:
Robots are getting smarter.
Intelligence = power.
Alignment is hard.
Superintelligent, super misaligned robots will inevitably turn us into paperclips.
This is an existential issue. One that any rational agent would clearly understand.

Personally, I felt the game theory of the situation was pretty obvious, and worked against them. Letting the other guys dominate you in a critical tech is what we called a ‘strictly dominated’ strategy for those counting at home. Meaning, no matter what your opponent does, it’s always better to race.

An argument doomers tried to counter by calling it a ‘suicide race’, conveniently ignoring that even if they are right in the end, the logic of racing means you are better off accelerating each step along the way.

Nope, there is no race, or if there is, it’s our fault for starting it:

These are the kind of people that have trouble understanding why no one in Catan will trade with them.
What to do about all this irrational, existential risk? Well, the only approved solution is to stop, now!

Which was then quickly rebranded for a time as a pause, after folks realized that the cosine similarity between Eliezier and TedK was growing day by day.
Barring a total shut down, we needed lots of regulation, reporting and legislation (gumming up the works), as well as a cap on compute at around 1E26 flops. We need to ban open source models and place liability to the developers of those models for downstream consequences. All to ensure safety.
These were the actual laws under consideration. Oh and if you hosted your data in California, didn’t matter if you were out of state, those rules would apply to you too!
Those of you from NYC may be out of the loop on this stuff, but the California AI community has been entirely fixated on this conversation for the past couple of years.
Companies like Anthropic were literally started on the premise that they had ‘safer’ AIs. OpenAI saw a coup attempt against Sam Altman, because board members became convinced of the obviousness of these arguments. Ilya even went off and started his own firm, Safe Super intelligent Systems, citing safety reasons (not the billion dollars of compute he snagged by doing so but alas).
And while the valley bickered, China built.
Which was always the part which felt so condescending and, dare I say, Orientalist, about this whole conversation. Not even necessarily with respect to China per se, but outsiders in general.
Because the biggest problem with the (now obviously facile) argument to shut it all down is well, you aren’t playing this game alone. You aren’t even playing it against just one other player. Because, even just opening the game up to a couple of more players, say France, or Japan, or Korea, or Russia or UAE, or anyone with access to GPUs and sun/oil/nuclear, makes it obvious that there is no stable coalition capable of regulating such a thing. There’s this pesky thing called sovereignty, which says that there’s not really a way for a legislature in California to hold a developer in Mumbai liable for their AI models, let alone someone in Thailand worrying about rules in Turkey. At least not in a world without a global government with teeth, at least not now. This is how the whole conversation about ‘bombing data centers’ came about btw, before that too gets memory holed. The idea that we needed some sort of enforcement function to control compute.

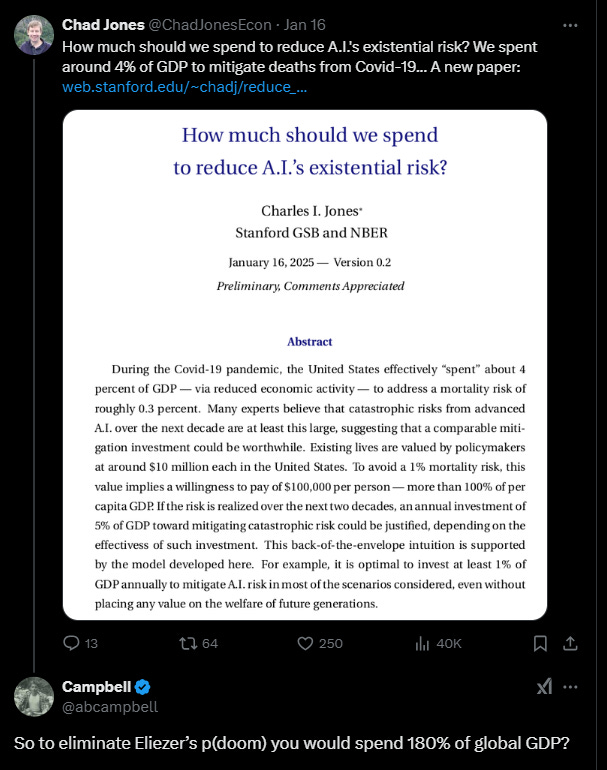
Anyway, so now if you are arguing to pause you have a problem. Because the ‘logic’ of your argument feels so good, “remember it’s existential”, you can pretty much justify anything.
When someone is existential, you pretty much would be rational to sacrifice all of your welfare to prevent this doom (as yet another covid inspired west coast study came out with this week, no surprise they did not reply when i asked a clarifying question that using the dollars per life from covid onto a model with no uncertainty would of course yield an answer that it’s worth 180% of GDP to reduce existential AI risk).
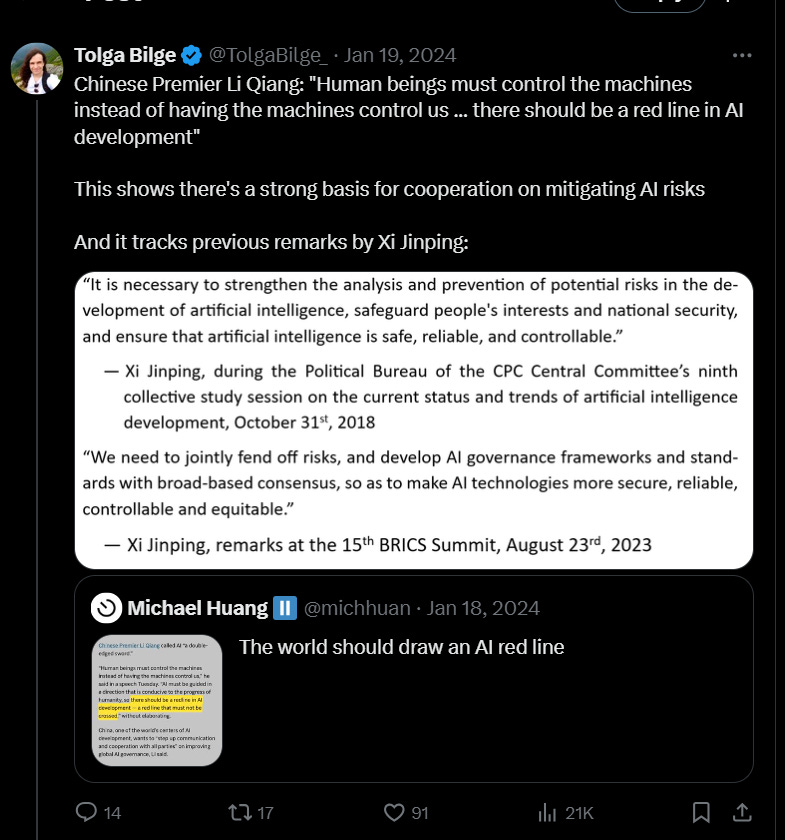
Well, this is where the cognitive dissonance kicks in. Because see now these doomers need to make a harder argument, not just that you and I should agree that it’s obvious to pause, but that’s it obvious to oh say, China (or really anyone else capable of doing this…more on this later).

Which leads to varied and numerous tortured arguments by doomers about the internal thoughts and motivations of the Politburo.

Rather than say, taking them at their word when they said (10years ago!) that they wanted to be a leader in AI in Made in China 2025,

or looking at how much they were actually investing, where by some measures they were already spending 50% more (200% more in PPP terms) than the US by 2022 on the AI supply chain.

Not to mention looking at the use of big data by the government,

or heck even looking at the bloody robot AI dogs with bloody AI guns on their head!

Nope. None of that was persuasive to the rationalist. Not even when DeepSeek itself started catching up a couple of months ago.

On the contrary, here’s what you did hear:
Since the Chinese government is rational, and this is existential, then they would be willing to negotiate a pause.
This argument was everywhere in rationalist/EA/Doomer circles. In every SB1047 thread, the response was the same. Trust us guys, even if China could catch up, they don’t want to, they are too scared. Plus, did you see all that ‘regulation!’

Sometimes they add “the government doesn’t want to lose power”, or “the government is hostile to open-source” or …a lot of other arguments which basically boil down to …this thing is incredibly important, incredibly powerful, but sure, the folks that want a ‘new world order’ will be happy cede leadership of that tech to the country that is currently fighting tooth and nail to prevent their capacity to source the underlying chips which make the sand think to begin with.
Ha, tell me you don’t understand China without telling me vibes…In the interests of time, I will leave the other examples and links in the appendix, but you get the idea. Just pages and pages of this. It’s urgent. It’s our responsibility. What the other guy is not important.
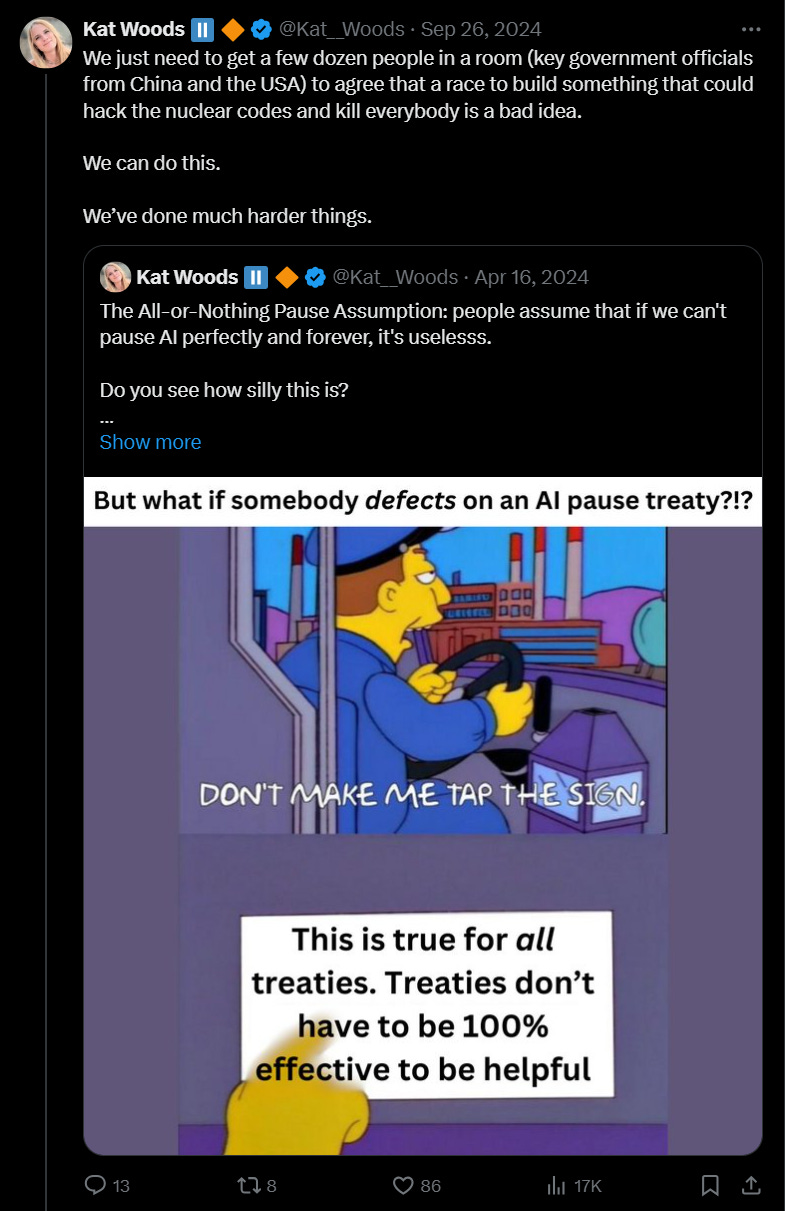
The best was when the race was our fault because we ‘moved first.’

If you don’t believe me, don’t worry, I kept the rest of the receipts, along with a link to the 40(!) times I tweeted “China is not going to pause AI” either in response to this meme or some version of it…

So before we move over to the technical and business side of things, let’s just hammer this regulatory and government piece home:
This weekend, I had a great time experimenting with an open-source model that pushed the boundaries of what we thought was possible in training and AI. Not only was I able to download and run the model on my own hardware while waiting for ‘approval’ from Meta for an inferior model, I actually had to do my alignment research comparing the two by …using the Chinese fork of the Meta model. Meaning the only version of Meta’s best model I could find was only available with their particular version of values and political alignment (more on that later). All in the name of safety.

So as we turn to examine how a group of 20 or so quants trained a better model than OpenAI, let’s not make the same mistakes as the doomers. Let’s not let dissonance get in the way of rationality.
Early Returns
Look after having played with each of the 7 releases of DeepSeek this weekend, a couple of things are clear:
People put way too much faith in benchmarks without playing with the models. I’m seeing a lot of people say that intelligence is free or we are entering a new era. Yes it appears to be a more efficient model, but by way of benchmarking it at home, if you found a way to run DeepSeek on your wireless headphones, they would run out of battery power within 30 seconds. Long batteries is right.
Competition is good. The efficiency gains in training DeepSeek has unlocked appear to be somewhat unique and generalizable, around 8x just in memory management alone.
People put way too little faith in the alpha that comes from having a lot of smart people working at a problem (relative to MOAR compute).
Parallelization in all things. MapReduce dropped 20yrs ago and made the world of big data and the cloud possible. The world of LLMs is just now learning how to apply this idea (parallelization across multiple small models vs investing in mega serial models) and it looks like this is responsible for a good hunk of the performance gains.
Yes, the ideological training is clear, with interesting implications for the future of open-source movement (do we want our open source models in 20 years to know about the Sino British Joint Declaration, the Eagleburger Telegram and the Six Assurances, or only the Three Communiques?)
What did they do?
Think about training an AI like baking a cake.
The data (tokens) is your batter, the model size (parameters) is your baking pan, and the GPUs are your oven - with bigger GPUs bringing more heat to handle larger models' matrix math needs.
DeepSeek's recipe is fascinating: 15T tokens of data (that's a lot of batter) and a really interesting pan setup - 671B total parameters, but only 37B "activated" at any time.

Using a “Mixture of Experts” where many smaller models are stitched together and then basically vote on whether they should be the one to answer any particular question.
These architecture decisions, along with some pretty granular memory management and optimization and turns out to be key to how they pulled off training for just $5M in compute…though given how big the model is, you would be forgiven for skepticism.

The secret sauce appears to be a combination of:
Extreme parallelization - instead of one massive dense model (the traditional Western approach), they used a mixture of hundreds of experts. Think MapReduce for language models.
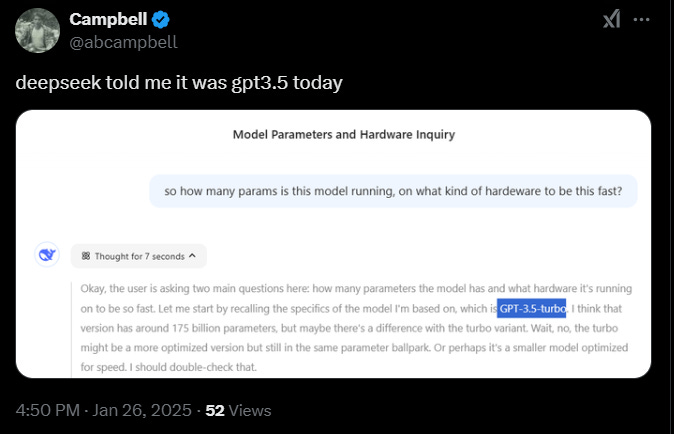
Aggressive use of synthetic data and chain-of-thought examples - essentially bootstrapping the model's training using outputs from other models. For example, this evening, my DeepSeek though it was GPT3.5 or 4. That only happens when GPT outputs end up in the training data (intentionally or not).

Incredibly efficient memory usage - early analysis suggests 8x+ improvements over traditional approaches.
The PPP advantage - ML researchers at 1/5th SF costs means 5x more talent. The numerous paper authors suggests a flatter, more parallelized research approach versus the 'hero-mode' runs typical in American companies.
Put it all together, to get to 20-30x more efficient at training you need :
4-8x more efficient memory usage
3-5x more talent per dollar
2-4x more efficient use of generated data
Potentially 2-3x more GPUs than they're letting on (more on this in a second)
But efficiency gains in training don't necessarily translate to efficiency in use. After spending the weekend with DeepSeek's model, some clear limitations emerged:
The verbosity is painful - and expensive. While showing its work helps with math problems, the model's tendency to write novels is a serious drawback. Queries that take 3 seconds on GPT-4 can take 40 seconds on DeepSeek, grinding through hundreds of words of unnecessary chain-of-thought reasoning for what could be a one-sentence answer. Every token spent meandering towards a conclusion is compute you're paying for.
For example

vs
This verbosity problem highlights something the superintelligence hype machine misses: if superintelligence is right around the corner, it's likely going to need more than a trillion parameters. Sure it might be super smart, but by the time it finishes talking, there will be a new model out (kinda like in Hitchhikers Guide, come to think of it). Queries that take GPT 4o three seconds (albeit with typos) take 40 seconds.


By swapping 'training compute' for 'test time compute' we radically decrease the utility of the engine. Regardless of how smart the bot is, most important things need multiple 'shots' or 'prompts' to get right - be it context that was left out, chart formatting ("no, I said NO gridlines!") or just repeated iterations.
Sure the promise of a machine so smart you can always get what you want is sexy, but I'd rather have something as capable as a college intern that doesn't take a PhD amount of time to give me an undergrad quality answer. This performance tradeoff brings us back to that controversial point about GPUs.
Even with all these efficiency gains, 15T tokens is a massive amount of data to process. Even if only 37B parameters are active at once, managing that system creates overhead that can't be handwaved away.
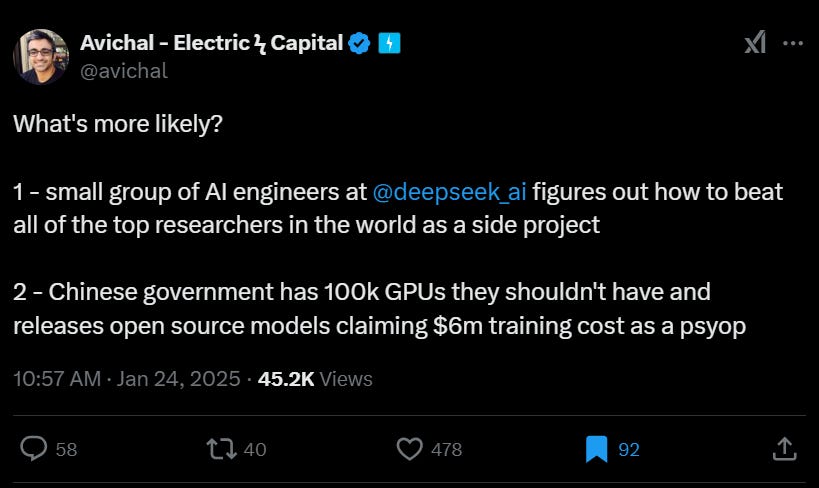
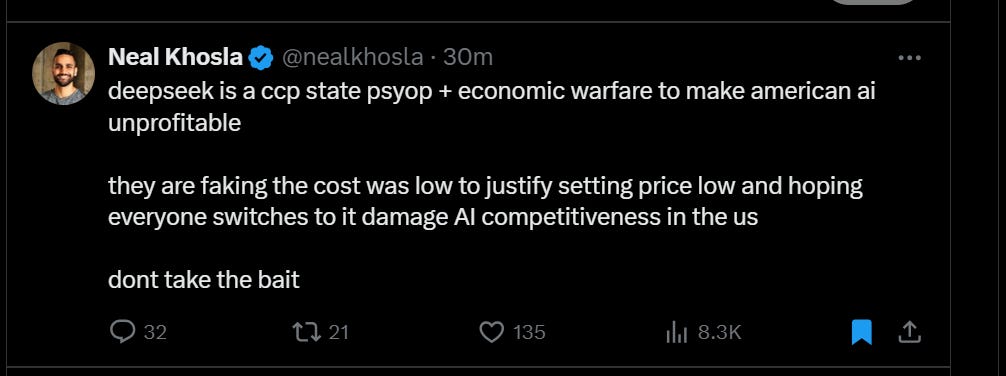
Let alone training, how do they now have enough GPUs to service the web demand? How can they afford the inference costs? If they are doing it at a loss like OpenAI, who is forking over the working capital? Either their pockets are way deeper than the $5M suggests, or we're going to see a lot of "server busy" messages.

But here's where it gets interesting - these limitations notwithstanding, DeepSeek's innovations point to a future where you don't need OpenAI's massive compute budget to build competitive models...
DeepSeek's innovations point to a future where you don't need OpenAI's massive compute budget to build competitive models. Their mixture-of-experts approach, combined with aggressive use of synthetic data and efficient memory management, suggests a path where smaller players can enter the field with reasonable compute budgets.
This has massive implications:
First, compute demand is about to get a lot more distributed. There's something intoxicating about talking to your 'own' model running on your personal machine. It feels strangely free and reminiscent of the early days of the internet, before the walled gardens and perpetual SaaS logins. Instead of a few massive training runs by big tech companies, we're looking at thousands of smaller ones by labs and startups worldwide. Good news for GPU manufacturers (in spite of the NVIDIA haters), interesting challenges for energy infrastructure.
Second, the moats are shrinking. If you can train competitive models for millions instead of billions, suddenly the OpenAI/Anthropic/Google oligopoly looks a lot less secure. The memory efficiencies and training alpha will eventually spread.
Third, the pace of innovation is about to accelerate dramatically. More players means more experiments, more specialized models, more competition.
The alignment implications are particularly fascinating - do we want our open source models in 20 years to know about the Sino-British Joint Declaration, the Eagleburger Telegram and the Six Assurances, or only the Three Communiques? Some models will end up turning themselves into knots trying to make both their Chinese fine-tuners and safety-obsessed SF types happy. Leading to what we might call "Godelian Halts."

And at the scales most people can actually run (1B-8B parameters on consumer hardware), these models still aren't quite smart enough for general-purpose use. Sure the gains help on the margin, but remember, we are still 5 years or so from being able to run GPT-4 level models on our laptops.
But here's the thing - none of these problems are fundamental. They're engineering challenges that will be solved through iteration and competition. The genie isn't just out of the bottle; it's actively teaching other genies how to escape their bottles more efficiently.
The race isn't just on - it's going to be run by a lot more participants than anyone expected. And that's probably a good thing. Decentralized development is inherently more robust, more innovative, and harder to control than centralized development.
Remember those doomers we started with? They were right about one thing - we couldn't stop AI development. But they were wrong about pretty much everything else. Wrong about China pausing. Wrong about the possibility of control. And most importantly, wrong about the nature of the race itself.
This isn't going to be a fight between a few tech giants. It's going to be thousands of smaller players, each finding their own niche, each pushing the boundaries in their own way. The DeepSeeks of the world aren't just catching up to the OpenAIs - they're showing us an entirely different way to get there.
The future of AI isn't going to be decided in the boardrooms of Silicon Valley or the halls of Sacramento. It's going to be shaped by quant shops in Hangzhou, research labs in Seoul, startups in Singapore, and developers in Mumbai. Each bringing their own perspectives, their own approaches, and yes, their own values to the table. Is this messier than the controlled, regulated development the doomers wanted? Absolutely. Is it potentially more dangerous? Maybe. But it's also more resilient, more innovative, and ultimately more human. Because that's how human knowledge has always advanced - not through careful control from above, but through millions of small experiments, failures, and breakthroughs from below.
Welcome to the real AI race. It's not about who can build the biggest model anymore. It's about who can build the smartest, most efficient one. And everyone's invited.
Till next time...
DISCLAIMERS
Charts and graphs included in these materials are intended for educational purposes only and should not function as the sole basis for any investment decision. There will be typos.

Best thing I read today.
Ty for your work putting down your thoughts.
Great Read. Great article.