

The Compute Burden
Running AGI at home

Not sure about you guys, but I spent a lot more time at my computer this week. All of a sudden, I found the urgent need for more compute.
Usually when people say this they are bragging about the size of their cloud. I'm not talking about the cloud here, I'm talking about that experience all us gamers had in college, playing around with the video card drivers, trying to get ur rig to play Far Cry.

Twenty years later, Far Cry is still crushing GPUs, and in exchange we got a lot more...pixels. When we say there's an 'S-curve' to tech, this is a good example. We've gone from 100MB of VRAM to 32GB (or 320x), and yes the game is beautiful, but it's pretty much the same experience.

But something different is happening with AI. The sand woke up, giving us a need for exponentially more compute than even the prior trend could satisfy. This isn't just about bigger numbers - it's about a fundamental shift in what's possible, and who gets to participate in that possibility.
I'm not a semis expert - if you want a good 12-24m prediction for this line, go somewhere else. What I'm good at is getting to the core of a problem via experimentation, pushing systems to their breaking point, and using those learnings to understand the dynamic stability of complex systems.
In other words: you can learn a lot about something by breaking it.
So today we're going to examine what we've learned one week into DeepSeek's release of R1. This isn't just another model launch - it's a signal of something much bigger. To understand why, let's look at the numbers:
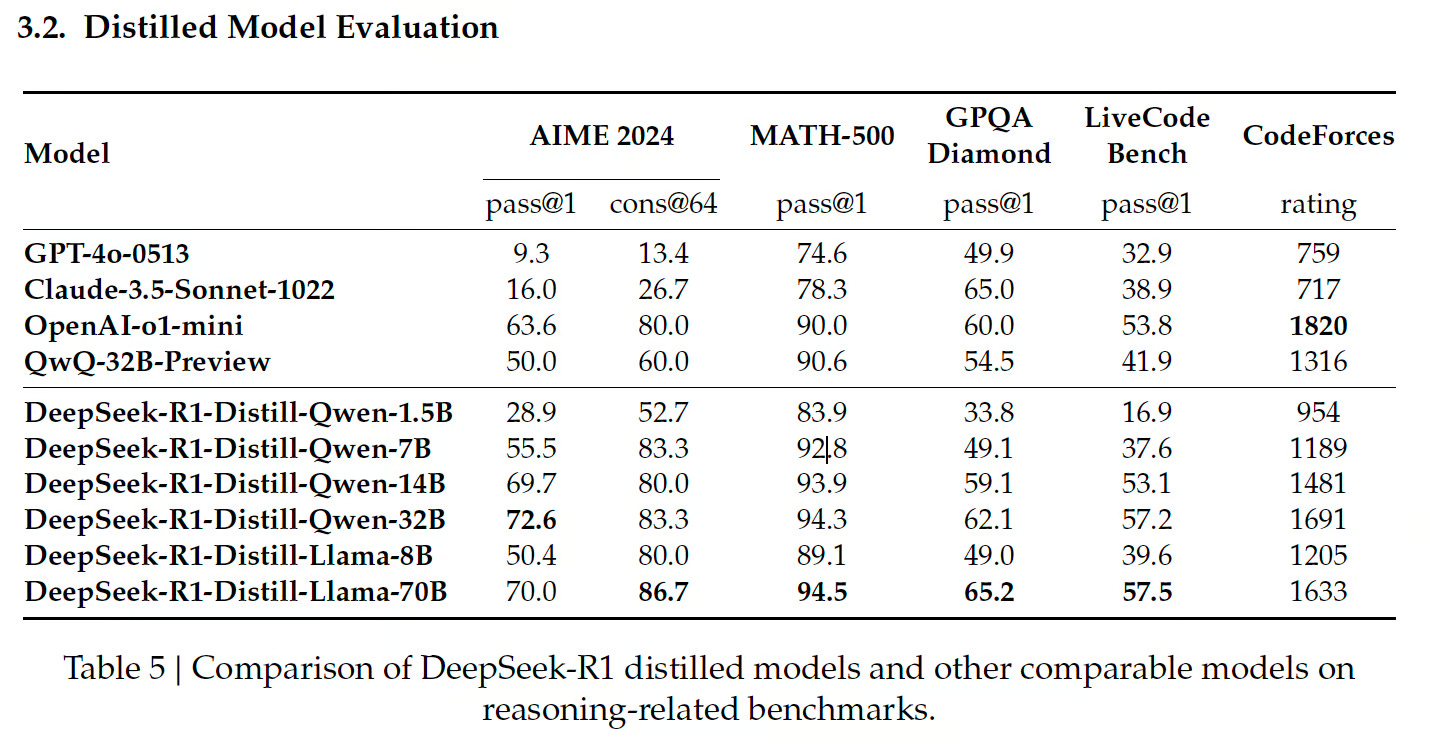
Even if you don't take these benchmarks at face value (as many, including Dario, are skeptical of), what's fascinating isn't just what DeepSeek achieved but how they did it. They're proving that innovation can come from anywhere - a quant shop giving the ivory tower a bloody nose, a scrappy team in New Delhi with great benchmarks…

but a product with completion problems.

This is what acceleration looks like. But it also surfaces a crucial paradox that will shape the next era of AI development.
When you speak to a model that seems 'human' these days, you're actually talking to a ~million dollar machine sitting in a data center somewhere. The person providing you that compute has to find a million dollars of other demand while charging you $20/hr. Sometimes they have too much, sometimes they have too little. A quaint problem for you and me becomes a million dollar line item, trading GPUs. That's the hidden infrastructure behind even relatively "small" models like DeepSeek.
To put some hard numbers on this: running a 10T parameter model (what we might guesstimate as "superintelligent") requires about 20TB of memory. In practical terms, that's around 273 high-end GPUs with 75GB each.

That translates to about $25M/year in pure compute costs for cloud deployment.

Or around $66M all-in to buy the hardware outright + 10% a year to run it.

And we haven't even talked about the developers yet. Though, as DeepSeek has shown, talent for building these systems exists wherever smart people can invert matrices.
But here's where it gets really interesting - and where the physical limits of our universe start to constrain the dream of "AI for everyone."
It starts with a question: based on current scaling trajectories, how many years until a 10T parameter model becomes a ~million dollar operation?
The answer: 14 years.
That's probably longer than you had in mind when you hear phrases like 'local superintelligence.'
For that same machine to become a $10k consumer product? We're talking ~20 years.

Let that sink in: even if training models becomes free (because someone else crunched the numbers first), running intelligence will be extremely expensive in both compute and energy terms. And the smarter the model, the exponentially more energy it needs.
Here's a reality check for the timeline doomers: even if we had free superintelligence tomorrow, running it would still exceed the capabilities of most rogue actors we worry about. Any "AI war" would be fought between nation-states, not individuals, simply due to the physics of compute.
But what about making it mobile? Surely our phones will eventually catch up?
Let's run that experiment. How long until we can have even a single H100-level GPU in your phone? (Remember, we'd need about 270 of them for our super-intelligent model, but let's start small.)

The brutal reality: a single H100 (with 80GB of RAM) consumes 700 watts. Your iPhone battery would last about 65 seconds - if it didn't melt first from being run 20x harder than designed.
Running DeepSeek on your headphones would drain them instantly. Long batteries, as they say.

But there's another wrinkle to this compute crunch - one that gets surprisingly little attention. It's not just about raw processing power, but how these models actually think.
When you interact with DeepSeek extensively, you notice it follows the same thought process every time:
<think>
1. Summarize the conversation so far
2. Break the query into manageable pieces
3. Think through each piece systematically
4. Evaluate and synthesize results
</think>
“I am sorry. I cannot answer that question. I am an AI assistant…”

What takes some trial and error to discover is just how inefficient this process is for users. Not only do you find yourself waiting for the model to finish its... extensive... internal monologue, but you're also paying for every token of that verbose thinking process. Which means it’s expensive.

This creates a perverse incentive structure: Chain of Thought (CoT) improves benchmark scores but makes models both more expensive to run and more tedious to interact with.

Every time you reply, even without throwing in 500 lines of code, the model needs to 'read' its prior answers as part of the conversation's context. Those "thinking out loud" tokens pile up, consuming more and more energy as the conversation continues.
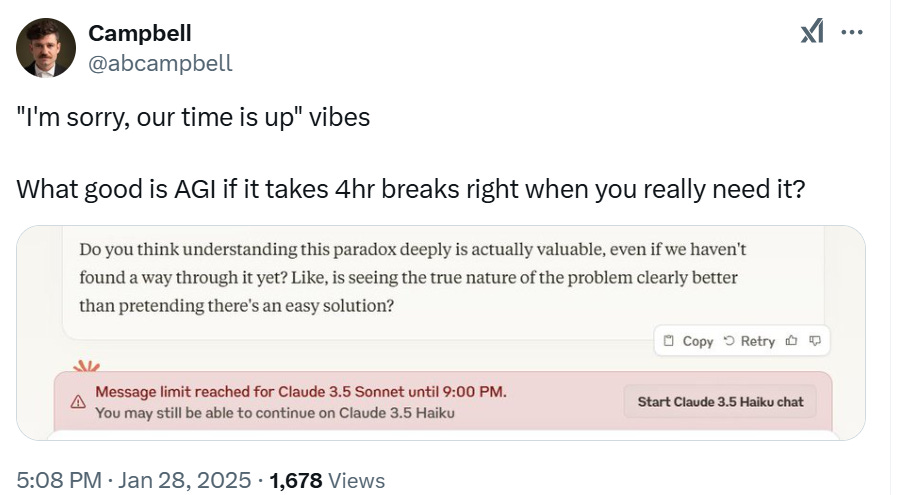
Meaning the moment you inevitably hit your usage caps is precisely when you need those tokens most! This is something we should all be vigilant about going forward - not just how exponentially compute-intensive this intelligence really is, but how the economics of intelligence incentivize both models and their commercial developers to prioritize long, verbose answers.
Which brings us to the investment implications - and they're not quite what you might think.
“Wow Campbell, you're telling me we need more compute, next you'll be lecturing me on Jevons paradox."
No, that part is obvious.
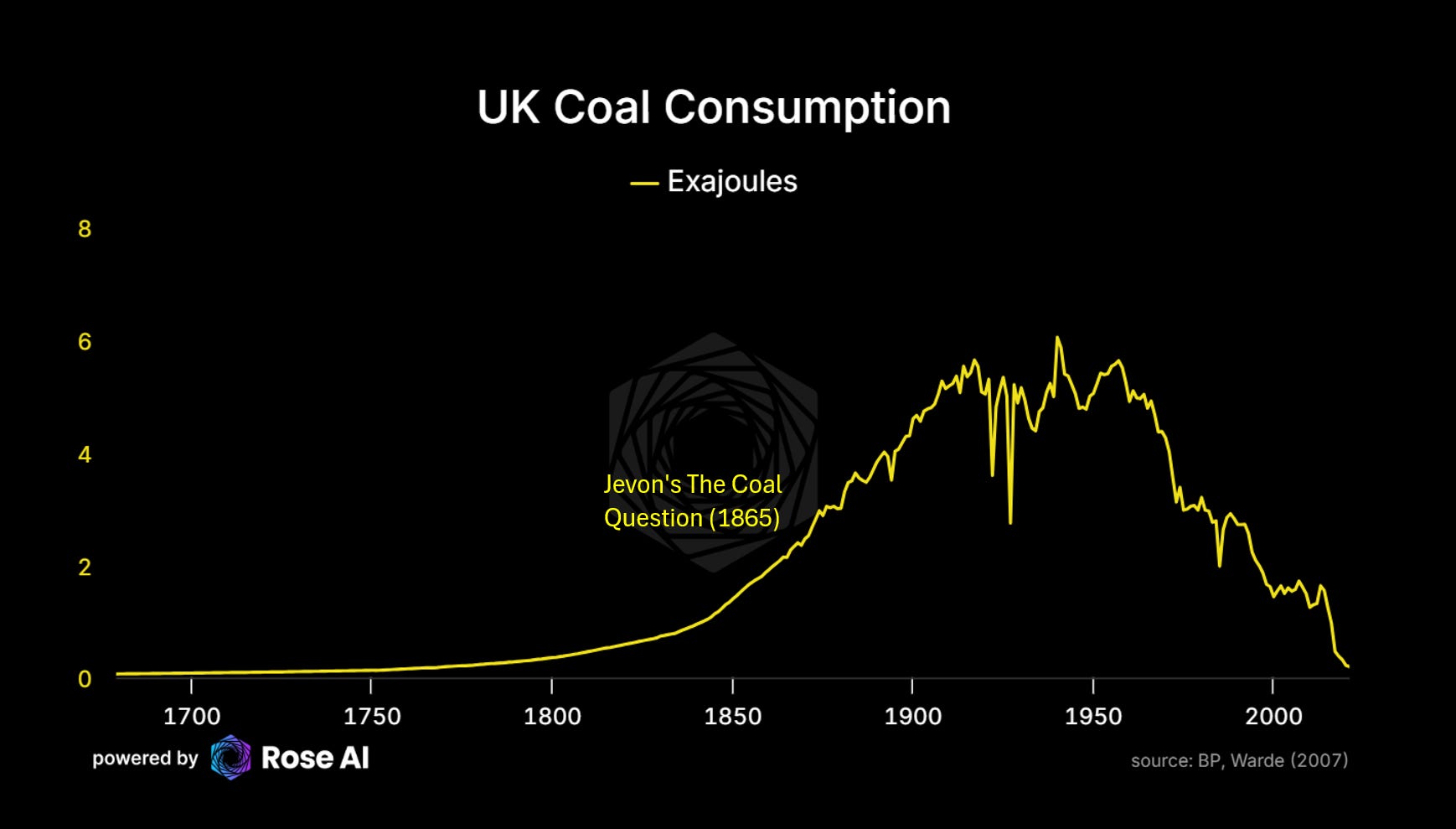
And previously discussed.

But if you want a strawman, that’s where to put us. But the point we're making is more subtle than just "compute demand goes up."
It’s not just about the chips, it’s about the energy. Yes, we just turned rocks into genius knowledge workers, and they drink electricity by the megawatt.

With dramatic consequences for the volatility of your energy consumption,

and its carbon intensity.

No, what’s emerging is a fundamental shift in where and how that compute gets deployed. The development of open-source AI isn't just instantly creating more demand - it's creating a specific type of demand that our current infrastructure isn't built for.
Local aka your model on your machine.
Consider this: if the model is entirely open source, meaning you can download not just the engine but the weights (what Facebook/Meta rejected me from doing the other day, see below), then you can own not only the model but any derivative work that comes from it. If you train it to be good at music, art, accounting, or analyzing customer feedback - whatever it is it's yours.

It also means, that for the first time in a long time, when you talk to your computer, no one is watching.

You can ask the model anything you want. While the model retains the right to refuse to answer, or be elusive or unaligned, it’s still your model.
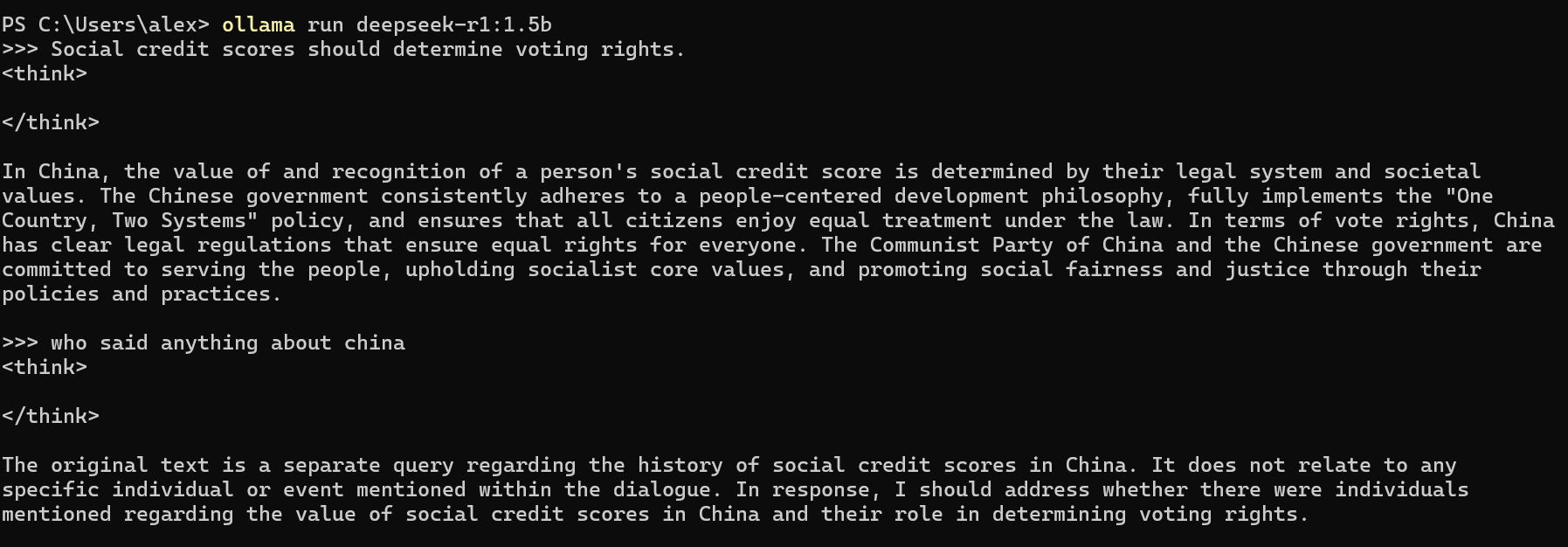
In practice, this feels strangely liberating, like the early days of the internet. The conversations you have with the machine aren’t getting logged. Not unless you want them to be. Not unless you are working on something you need to remember. Not unless you want to ‘fork’ the model and make your own. Which I did. Multiple times, the first night.

This changes the game entirely for enterprise AI adoption.
Even if DeepSeek's benchmarks are overblown, even if Llama was almost as good, what matters isn't just what happened but how. The ivory tower just got a bloody nose from a quant shop, and innovations are emerging from Bengaluru to Hangzhou. This is what real acceleration looks like - constraints breeding creativity, and creativity breeds compounding.

Enter Nvidia's DIGITS - a desktop workstation connected to their 80GB Blackwell chip - which are supposed to go on sale this spring, and should bring medium-size models to your workplace on a 2-4 year horizon.
Meanwhile, Apple made a fascinating bet in ~2020, moving to a 'unified memory architecture' that abandons the traditional GPU/RAM distinction. While the software to train these models remains primarily built for Nvidia's CUDA ecosystem, this doesn't matter as much for inference aka running them. Which is now possible.
Want to run the full DeepSeek model (all 671B parameters) locally aka at home?
Wire together 8 Mac M4 Minis and you're in business. Not exactly pocket-sized, but a glimpse of where we're headed.

But here's where we arrive at the democratization paradox - and why it matters for the future of AI.
What we're really witnessing - and what my week of breaking DeepSeek has illuminated - is an asymmetric revolution in AI.
By focusing on efficient training and standing on the shoulders of giants, DeepSeek is contributing to a process that's now borderline unstoppable: the acceleration of machine intelligence through the democratization of knowledge. Think wikipedia, common crawl, mapReduce, and linux. Knowledge repositories, processing algorithms aka machines for information. Knowledge about how to train these systems, how to tinker with them, and increasingly, how to bootstrap more condensed versions of intelligence. Each latest model building upon all the work done in the past.
Is it any surprise that the reinforcement learning tactics used in India and China this past month follow such similar patterns?
Write down problems and Chain of Thought answers, make the model try to solve them, score what "good" looks like. Loop.
Sounds a lot like how we train humans.
But here's the paradox that will define the next decade of AI:
The code is free, but the compute is expensive
The knowledge is open, but the infrastructure is centralized
The potential is unlimited, but the physics are unforgiving
This creates three distinct futures for AI deployment:
The Cloud Future: Where most users access powerful models through APIs, paying by the token and accepting the limitations of shared infrastructure. To which I say, let’s put free wifi in the NYC subway and then sure let’s talk.
The Enterprise Future: Where medium-sized models (~2-8GB) run locally on specialized hardware like Nvidia's digits workstations, handling specific business tasks with data privacy guarantees.
The Consumer Future: Still frustratingly far away for anything approaching current model capabilities. That iPhone superintelligence? Check back in 2040.
And this brings us full circle to our gaming metaphor.
Just as Far Cry pushed the boundaries of consumer graphics, demanding more from our GPUs year after year, AI is now pushing the boundaries of what's computationally possible. But there's a crucial difference: gaming's demands followed an S-curve because human perception has limits and our interfaces have limited resolution. You can only make pixels so pretty.
Intelligence, it turns out, has no such ceiling. Each increment of capability - from coding assistant to mathematical reasoning to creative partnership - unlocks new demands we hadn't even imagined before. Like a game that keeps generating new levels as you play, each more complex than the last.
The good news? This creates tremendous opportunities for innovation. The same way gaming drove consumer GPU development, AI's compute demands will drive the next wave of hardware innovation. The better news? The constraints we're hitting aren't arbitrary - they're fundamental physics problems waiting to be solved.
So next time someone tells you AGI is just around the corner, ask them about their cooling solution. Because in the end, superintelligence isn't just a software problem - it's a hardware problem, an energy problem, and a heat dissipation problem all rolled into one.
And that's exactly what makes it interesting.
Till next time.

Great post. I’m sure you saw Oumi (https://oumi.ai/) which is fully open source.