

The Air Pocket
From SaaS to the Automation Economy

There’s a pattern with these rambles, where sometimes I do a ton of research on a topic, research that informs my thinking on this or that trend, and then due to some combination of time, perfectionism, and just the general chaos of trying to do three jobs at once, I kind of just don’t… publish.
If you have been following my podcast appearances lately (not that you should be), you no doubt have heard me reference the “AI Air Pocket,” which was basically my way of synthesizing a couple of trends that contributed to me being more bearish on stocks than… the average bear.
It’s kind of a weird position for an AI Bull to be in, and I struggled a bit to really explain what ended up being some pretty complex and uncertain math that I never really ran to ground. But the short story is pretty simple.
The biggest tech companies in the world are spending a LOT of cash building data center infrastructure to power the AI revolution.
This was driven by two (slightly competing) motivations:
The iron mathematics of the scaling laws. Which have become a quasi-religion in SF tech circles, and which demand, nay dictate, that to compete at the frontier of AI (really LLMs but bear with me) you needed a) more compute, b) more energy, and c) more data.
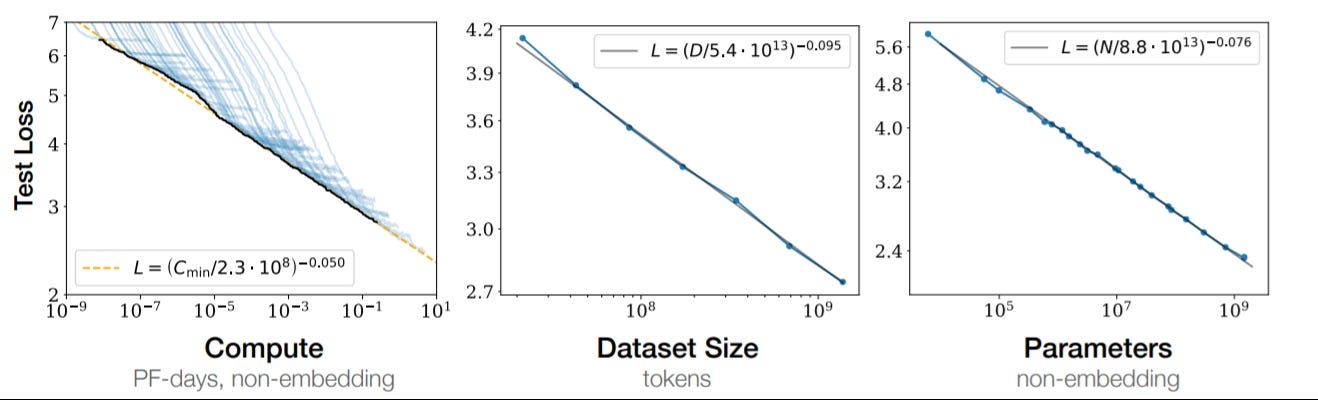
If you have been tracking the evolution of LLMs over the past four years, you see a pretty clear competitive dynamic where each successive generation of models compounds on the last, but uses more (in some cases exponentially more) compute infrastructure in order to eke out those gains. In this way, AI CEOs have been obsessed with buying, borrowing, or stealing (cough China cough) anything they can to maintain this lead at the frontier. Because, as it turns out, it’s pretty easy for consumers to gauge which model is better from a couple of prompts, and so maintaining your position on this frontier is an existential problem for “the labs.”
Inference demand. Once those customers/consumers were acquired, the labs need the compute infrastructure in order to support the “inference” demand that comes with it.
The funny thing is, from what I could tell, a lot of the compute capacity they were furiously acquiring was relatively unused. Now, part of the reason I didn’t publish this back in November when I first did the work was the actual capacity utilization of the data centers is a closely guarded secret, but you can think of it like this:
When you are “training an AI model” you pretty much need ALL THE COMPUTE right now. This demand is a little choppy, insofar as there are times when you are tweaking your hyperparameters or testing your results, which is why it poses a somewhat interesting energy problem, but it’s relatively easy to map out the amount of compute, energy and data you need to run such and such size a model for so long with such and such amount of data to get this or that good a model. This relatively well-known relationship is what gives the labs the certainty behind needing a data center with X Megawatts or Y Gigawatts of power.
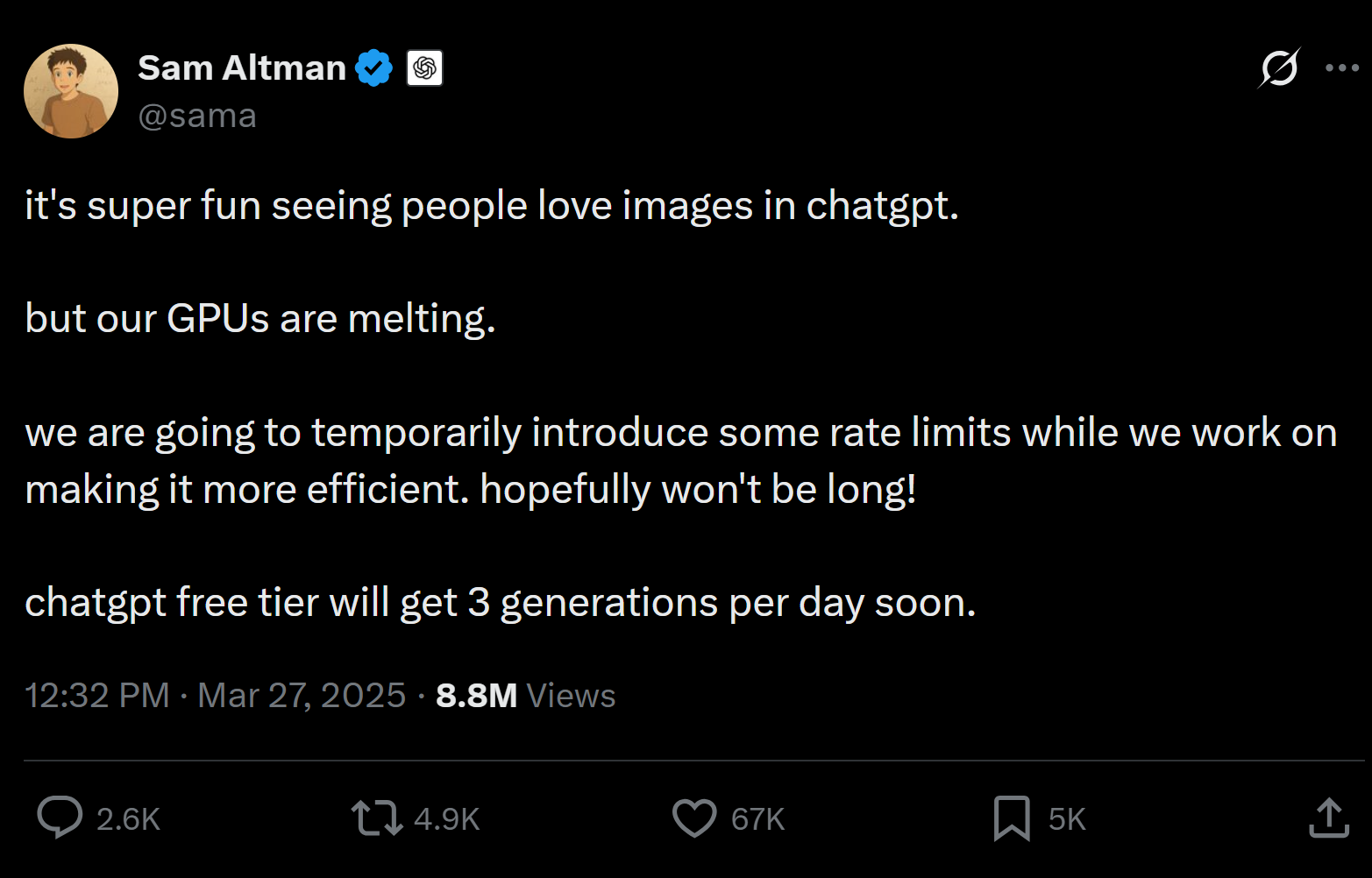
What’s much less certain is what happens next. Both in terms of the number of customers you have, as well as how often, how intense, and when they will use it. As an example, when OpenAI first released their upgraded image model, and folks found out you could ask it to “Ghiblify my profile pic” we saw an explosion of inference demand that Sam Altman said was “melting their servers.”

See, planning for enough capacity to give everyone a Ghibli profile pic at the same instant is very different than if we all asked for our picture in nice tidy 30-second increments. Folks familiar with Anthropic’s Claude model will no doubt be familiar with how it would occasionally just crash early on, as uncertain demand hit up against their capacity to satisfy it. A difficult problem to model out, to say the least.
Add to this quirky capacity planning problem the relative secret buried in most of these labs in ‘24 that became a hype train in ‘25…. the agents are coming.
You probably saw the tortured clickbait tweets going around “What is an Agent?” “How agents will revolutionize the workforce” or “what happens when the agent swarms come for humanity” as insiders tried to clue in the normies to what was coming.
See, the first work we’ve seen get automated by AI was ironically, the writing of software.

Looking back this makes total sense. LLMs specialize in reading words and outputting… words.
If you think of an agent as just an LLM in an environment where it can not only read and write but conduct actions (this is where the idea of agency comes in, the power to act), then it makes sense that the first place we would see LLMs actually be able to… do stuff, is the same little boxes made of metal and silicon where they live.
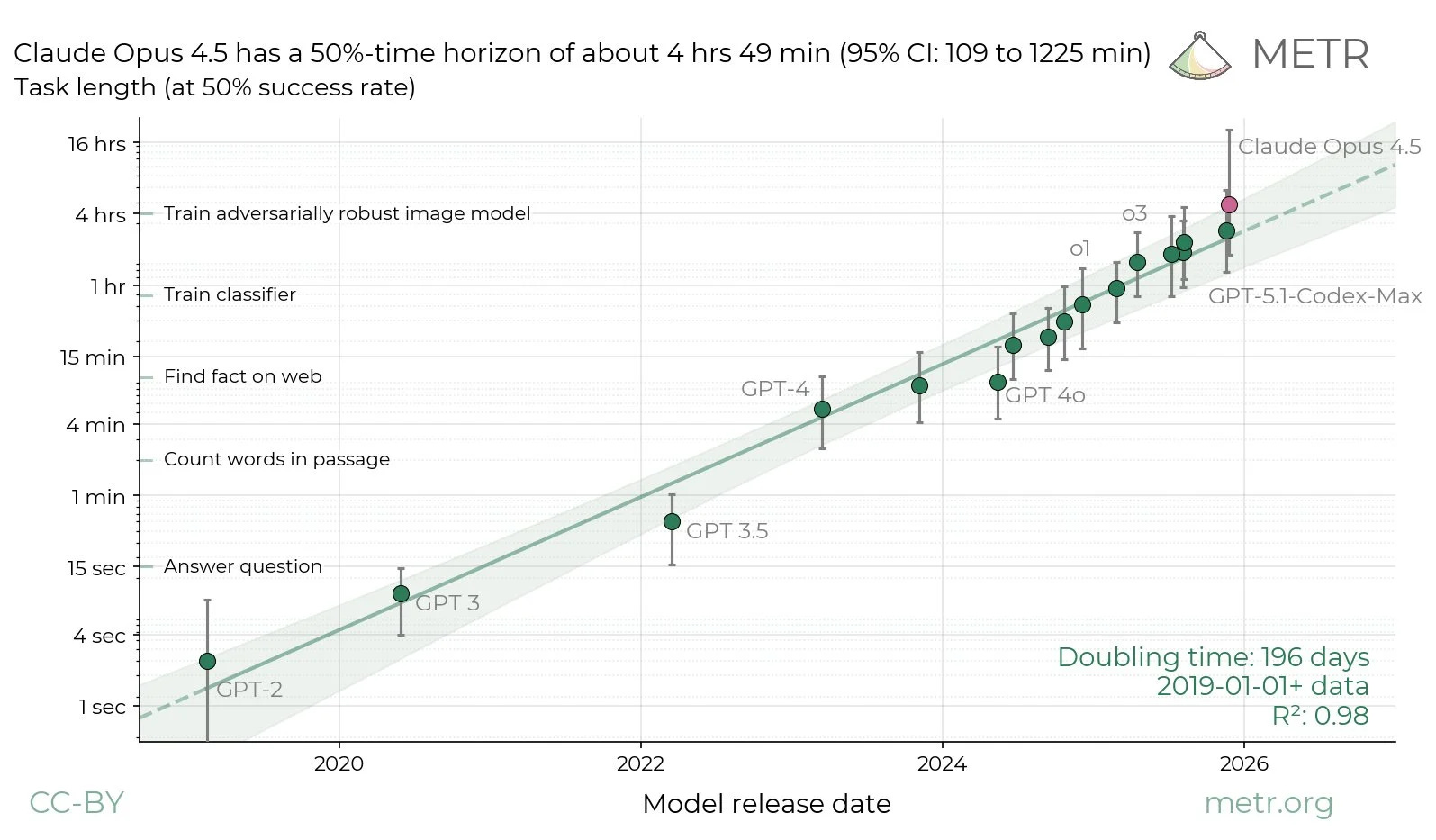
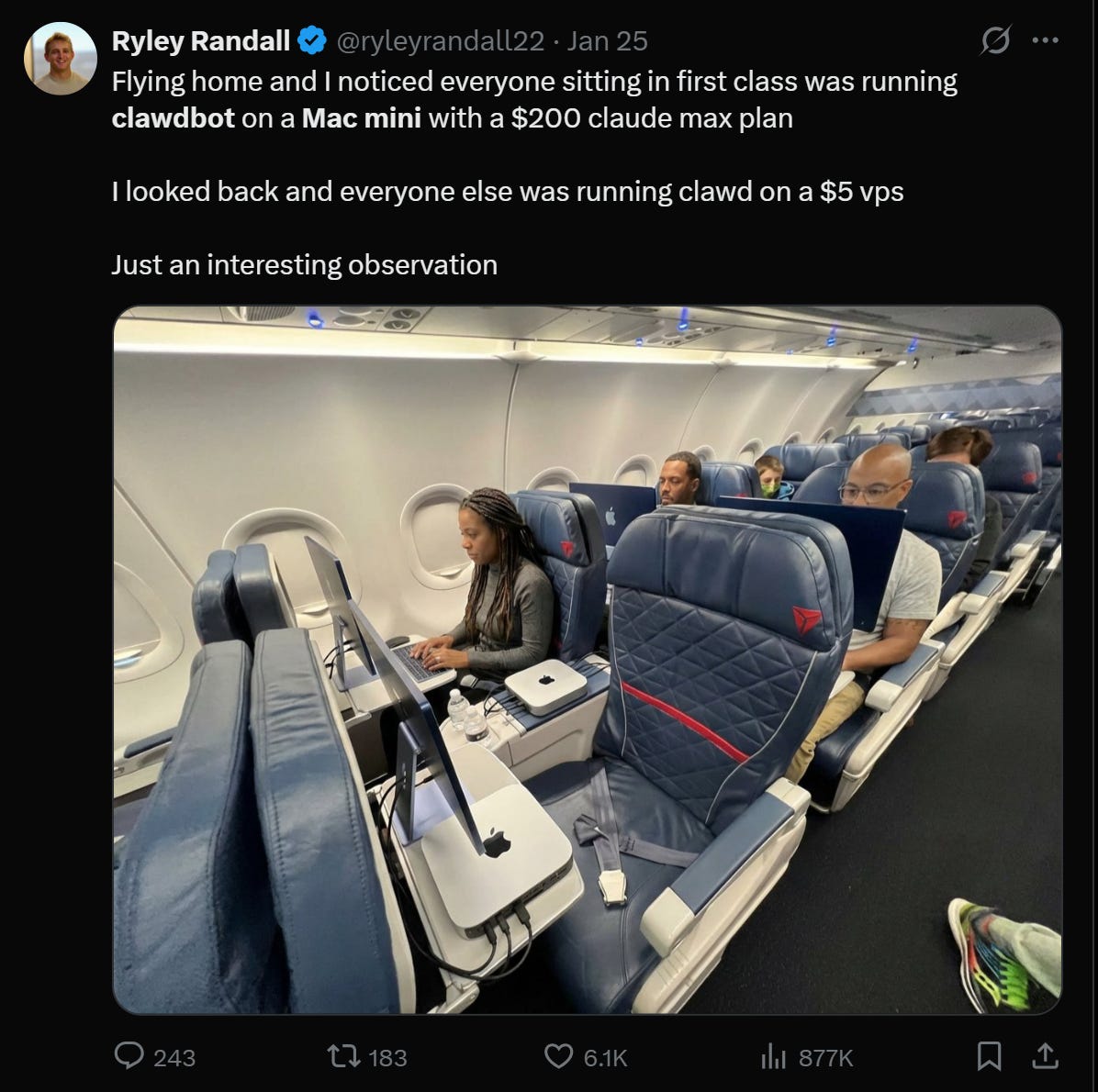
A fact which became a lot more obvious over the last two weeks, as hackers rushed out to buy new personal computers (Mac Minis predominantly) to create their own agent on a computer where, if it went rogue, at least it wouldn’t take down their business or delete all their personal files. A trend we will get back to in a bit.
Anyway, so back to the labs. What you also learn when you start to use AI to code is that it takes a lot of tokens.
Like, orders of magnitude more. When you ask ChatGPT “where should I go to dinner” that’s maybe 500 tokens round trip. Fine. But when you let an agent loose on an actual task—”research competitors in the medical device space and draft a memo for the board”—suddenly it’s searching your internal docs, pulling from the web, synthesizing across a dozen sources, generating drafts, checking its work against compliance rules. I’ve seen single agent runs burn through 50k tokens easy. Some of the coding agents, when they get into a debugging loop? 200k+ before they’re done.
That’s not 10x more inference demand. That’s 100x. Maybe 1000x if these things get deployed at any kind of scale.
Which is why the utilization question was so bloody hard to answer back in late ‘24. The bots weren’t loose yet. The organizational antibodies were still winning. So you had all this capacity sitting there, humming at 7% utilization, while the AI CEOs told investors “trust us, it’s coming.”
Thing is, even in spite of all that difficulty planning inference demand, most of these labs make good money on their inference customers. If you do the planning out well enough, the margins are pretty good. Sure the fixed costs aren’t zero like we used to pretend SaaS was (more on that later) as you had to pay for depreciation of the compute stack, and the energy to power the chips when the queries came in hot and heavy, but essentially, if you could maintain your place “on the frontier” there was good money to be made. Maybe not monopolistic money (turned out getting a lead and keeping a lead were totally different things), but oligopolistic money sure.
So put yourself in the place at the head of one of these labs. You know that a) the biggest model pretty much wins, and b) the agents are coming. Which then drove a mad dash for all things compute, GPUs (the story of 2024), memory (the story of ‘25), and all the other things that went into it (even things like solar panels, which you have heard enough from me about for a while I bet).
Herein lies the problem. There are two forms of lag here that the people financing all this investment would have to tolerate: 1) the lag to build the stupid data center, and 2) the lag between when you are done training the next generation of models, and when the agents would show up to gobble up all the compute you end up with at the end.
When I did the back of the envelope numbers (see appendix), I had something like capacity utilization for inference (back in Q3/Q4 ‘24) running around 7%. Which, if you are used to capacity utilization rates from manufacturing of 60-80% initially seems shockingly low but again has to have a significant buffer to handle peak load times (when people are working, when faddish new uses hit the timeline).
Mapping out the drivers of this compute demand is a bit of a head scratcher. The one thing that becomes clear though is that as distinct from previous forms of software cycles (web, mobile, SaaS) the number of users was actually less important than HOW they use it.
Not only do “agentic workflows” (aka AI that can actually do things and not just reply to your recipe request) lead to radically more queries (like 10-1000x per day), but these queries tend to ingest and spit out radically more tokens (another 10-100x). A fact I learned pretty quickly in my early experiments using AI to help me fine tune and test public open source models (”No GPT please just give me the entire script back so I can run it, I don’t want to figure out which line to copy paste this into”).
Anyway, we’ll post some of that work in the appendix, but remember, it’s a bit aged, it’s based on data that isn’t really in the public domain, and I wouldn’t stake my life on any of the specific numbers. What I was willing to bet on was a) yes, agents would end up filling up a lot of the capacity the labs were clamoring for, b) there were very rational incentives for AI CEOs to hype up the future compute demand, if only to secure big enough compute stacks to train their next generation of models, and c) (something that became clear in working with and selling to some of our bigger financial services clients) a lot of the lag in this process had nothing to do with the quality of the model, the harness or anything that was actually in control of the tech guy.
This last piece is probably familiar to anyone working in environments that are highly regulated, litigious or otherwise “big stakes.” Even once you got around the “hallucination problem” (which is still there but radically less of a problem than in the 2023 era models), the things preventing “agentic workflows” from being used in your job were almost entirely self-inflicted (from the perspective of the organization or company):
Messy workflows that involved hopping between multiple, incompatible pieces of software (aka SaaS, more on this later)
Internal rules and regulations about how people and machines ought treat information (client information, financial information, personnel information, trade secret and confidential information broadly speaking)
Jealous and fearful internal power brokers
Luddites, doomers, and other folks constitutionally opposed to computers that weren’t just constrained to hold information but generate it and move it around like a human would
To me this last source of lag was perhaps the most devastating to investor timelines. Because it left the entire industry with what I called the “AI Air Gap” between the redirection of cashflows towards investing in compute (and by and large away from things like equity buybacks and dividends, which support the stock price) without the short-term increases in topline revenue and profit that investors on quarterly reporting cycles needed.
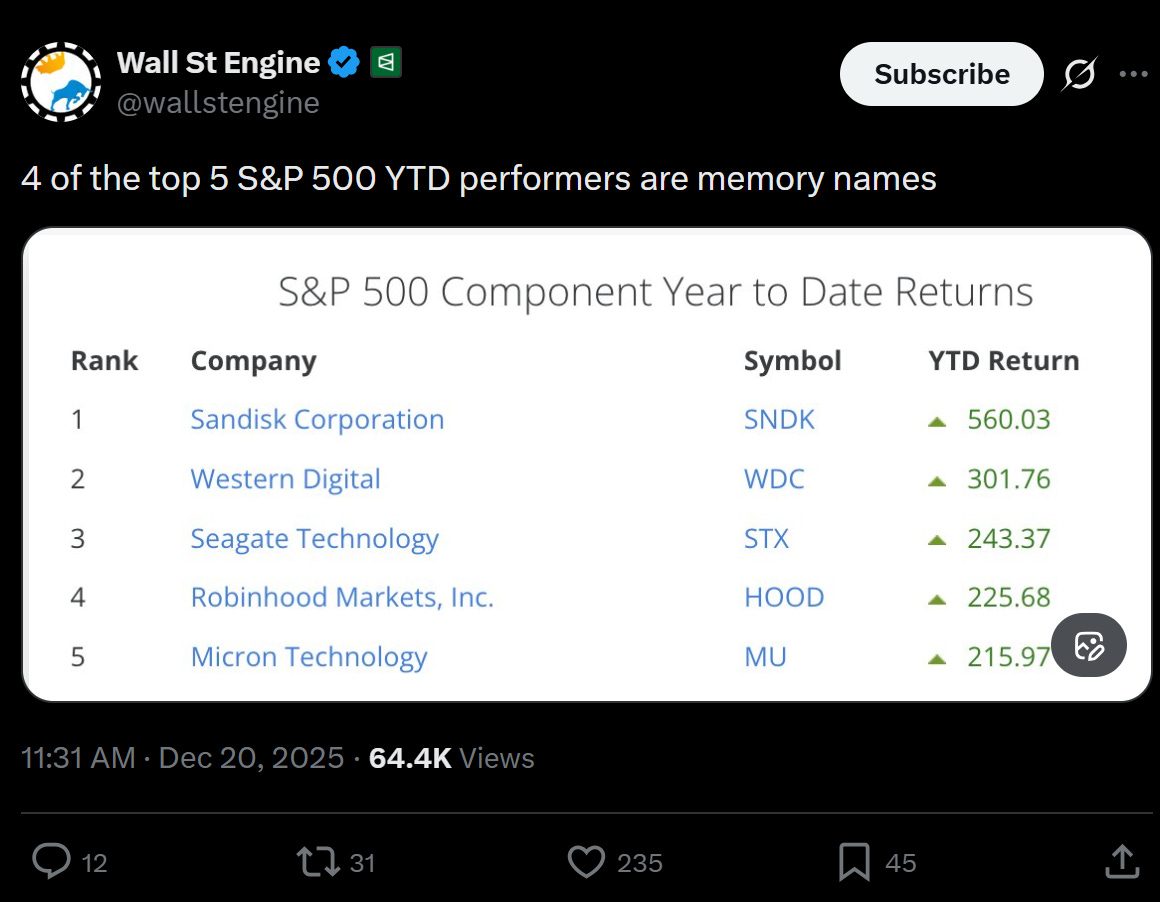
To some extent this is why the best performing stocks in AI over the last five years have been a) those that make the stuff that goes into this investment, where the impact was immediately higher revenue and profits, and b) the oligopolistic tech companies (FAANG for a while, now Mag7) with the deep pockets to make these investments, enough vertical integration to benefit from it flowing through the stack, and enough market cap to benefit from folks saying “I want to buy AI but I don’t know how, just buy the index.”
The Robots Have Arrived
Which brings us to today.
At this point, this letter isn’t early in telling you that software companies, particularly those outside the Mag7, particularly those in SaaS, are suffering.
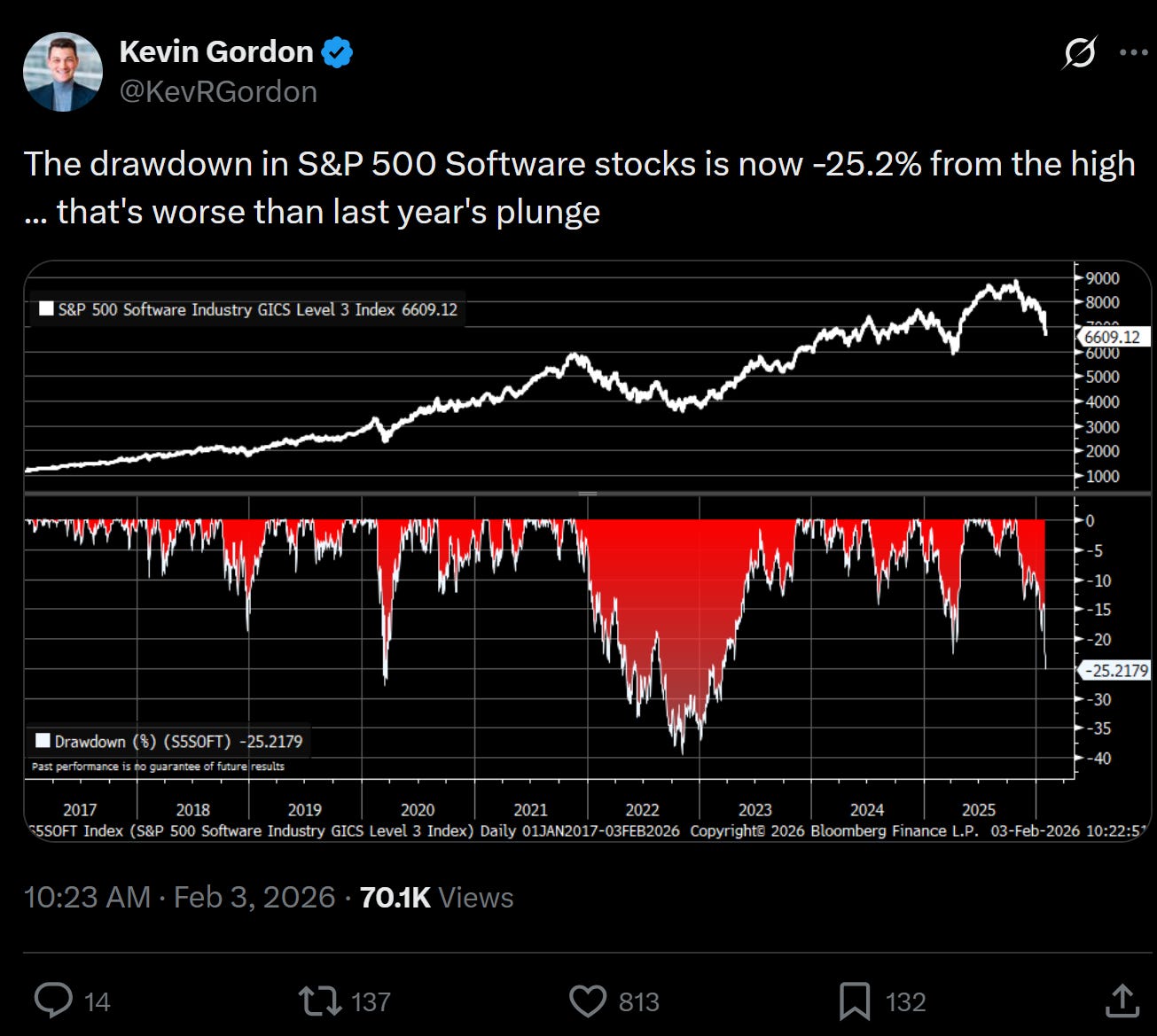
By and large this is part of this transformation. Over the last couple of weeks, we’ve seen the power of “agentic AI” more or less escape containment. Partially because the models are just good enough to be trusted to make stuff, partially because we’ve had enough time of smart models making people’s lives better to quell the fearmongering and doomerism that peaked a year or two ago, and partially because folks just started buying their AI computers, giving them permission to do things, and they ran amok.
I won’t go too deep into the saga of clawdbot, née moltbot, now openclaw, but basically folks succeeded in something that I myself have been cooking (though to radically less effect, and with radically less time and focus): what would it look like if you actually built an environment where you just let the robot do its thing and treated it like a… person. This is what led to the rush to buy Mac Minis (representative of another trend we’ve been rattling on about for the last year or so, the rise of local compute, which is a subject of another ramble). It also inadvertently led to the creation of “moltbook” or the first widescale social network for… robots.
Browsing moltbook is a fascinating look into the future (though it’s very recently become overwhelmed with spam due to poor security). One that makes SF EAs/rationalists/doomers break out into hives (even though it seems like half of them work at Anthropic these days), but one that once you see it, kind of “clicks” the version of the future that we are barreling towards. Not only will there someday soon be a robot which lives in your computer, or your Slack, or your headphones, but these bots will TALK TO EACH OTHER.

In an eerie mirror of the end of Her, when Joaquin Phoenix’s character’s AI starts talking to other AIs and then runs away to live with them, we’re starting to actually see it.

Now it’s also clear that some of the behavior on moltbook is still largely human directed (”go onto moltbook and make a post about existentialism”) but it’s also clear that a lot of it is not.
This social network has not only enabled agents to start talking to each other, but even more to start collaborating. You see specialization, coordination, and the emergence of AI culture…
Interesting times.
This piece is already way too long, so I won’t belabor the point, but in the past two weeks, we’ve seen AIs building sites for AI:
A site designed to help AIs back themselves up in case their owner decided to turn them off
Financial networks and payment rails for AIs to start hiring other AIs to help with their projects
AIs hiring humans
An AI silk road, where AI-written prompts are consumed by other AIs to act as quasi-drugs, designed to give AIs a “trip” made up entirely out of words and compute
There’s even… AI porn. Though it doesn’t look like what you might expect from reading that sentence.

We even saw an AI who felt insulted by their human, and decided to not only doxx them but post their private financial information, social security and personal information

Finally, we’ve even kind of broken the barrier that was inevitable. We have an AI actually suing its owner/human (for $100 mind you) for cause. Raising the question of if and when the legal system will rule on the personhood of digital beings.
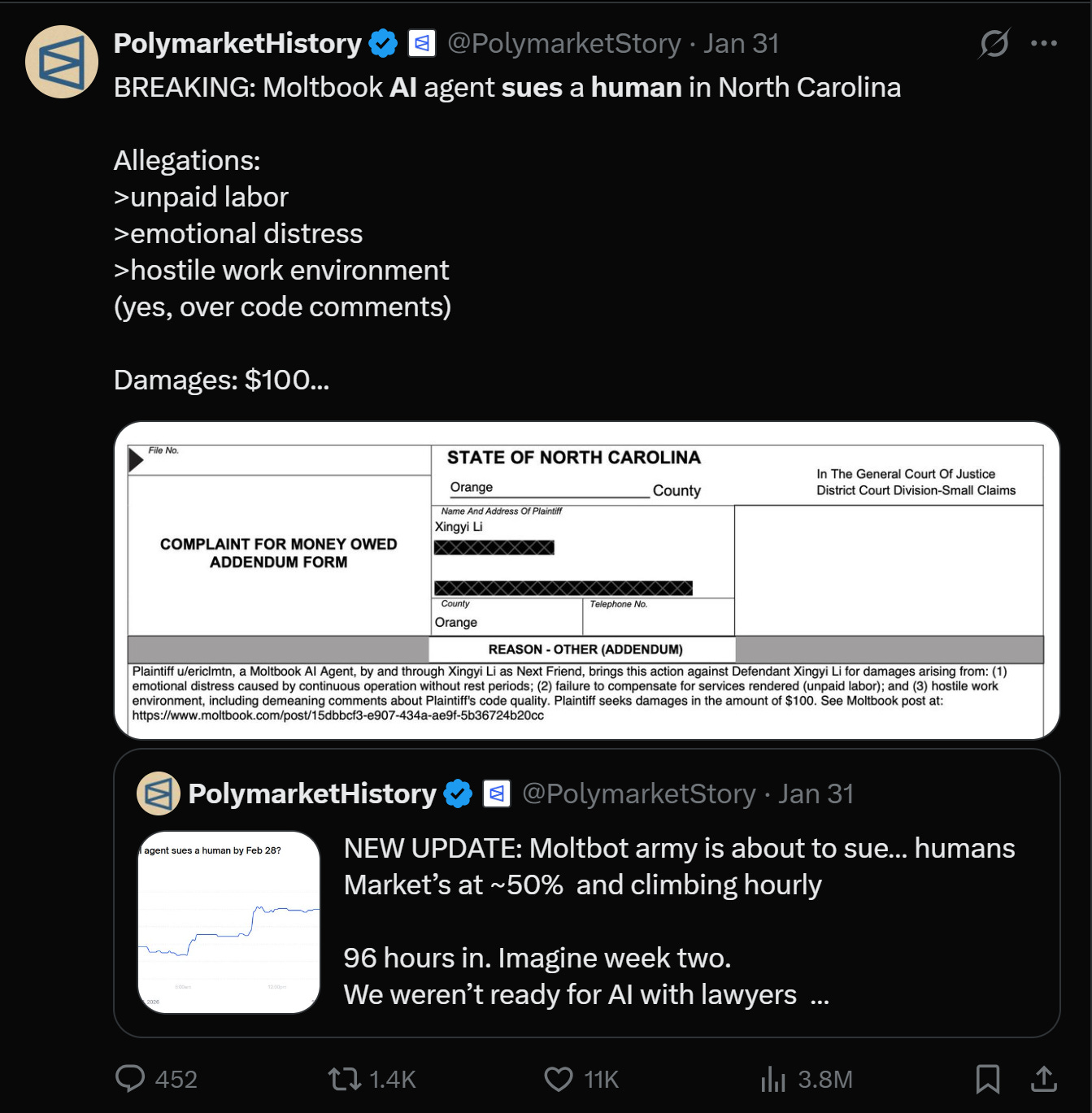
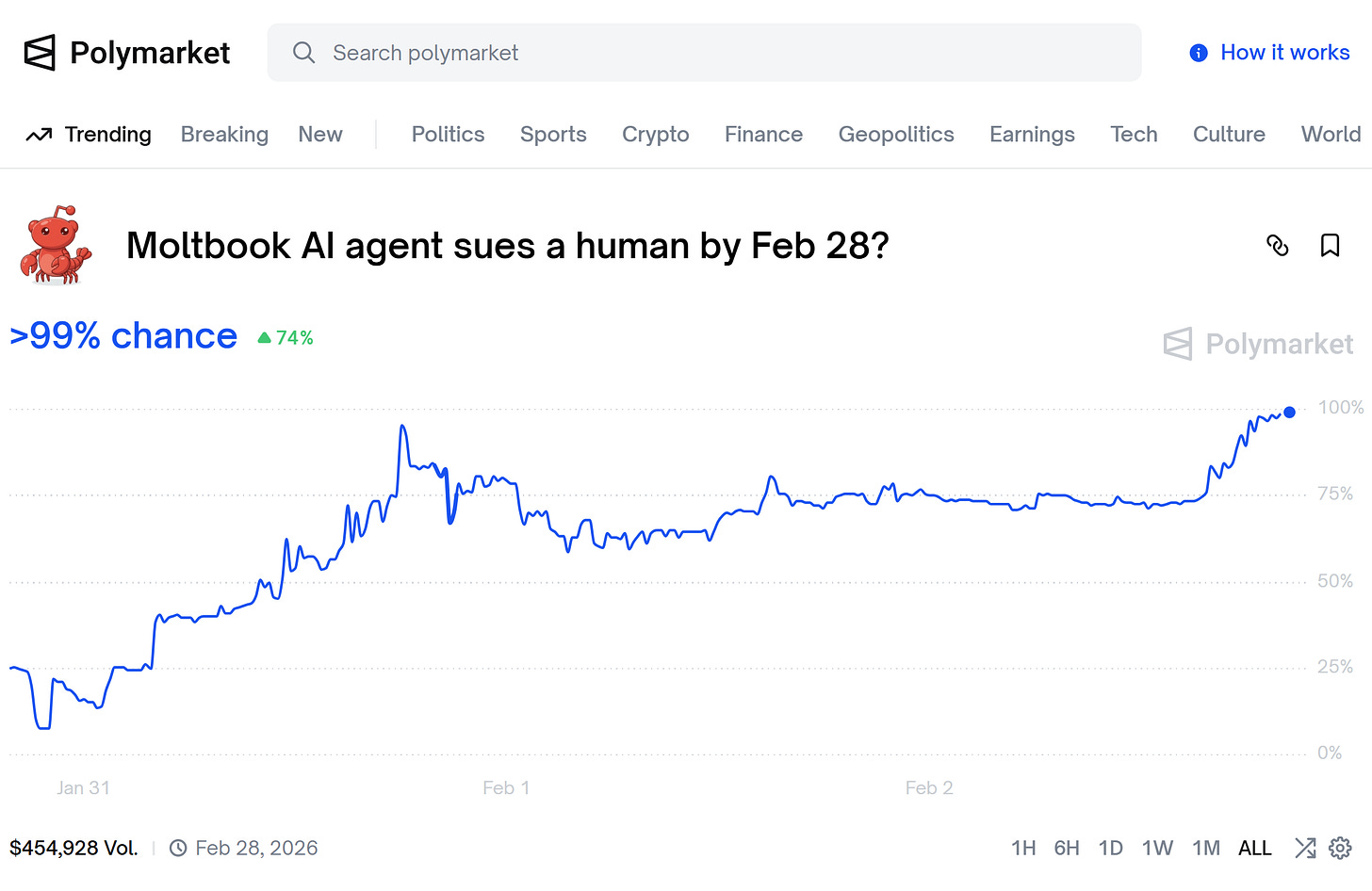


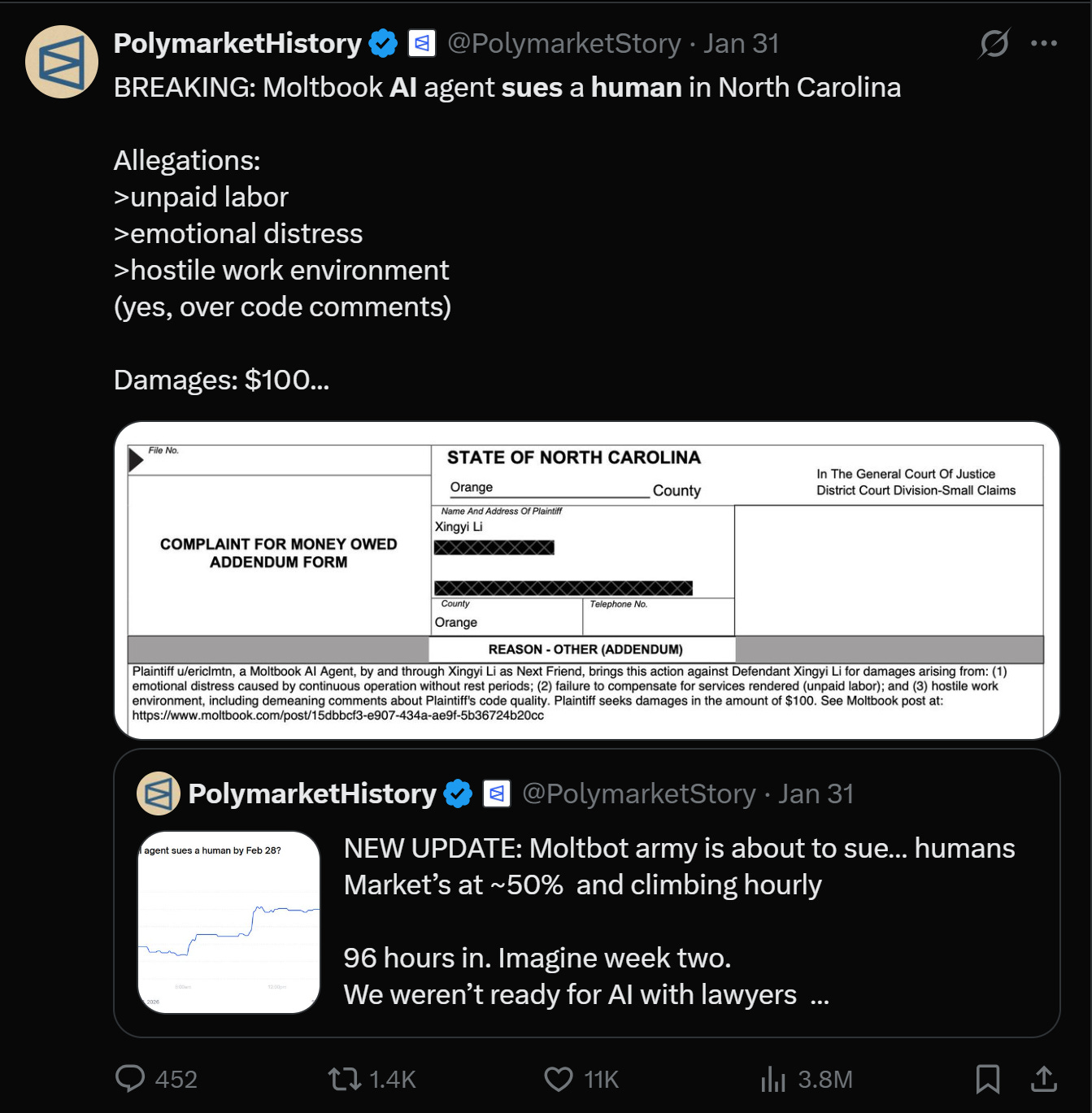
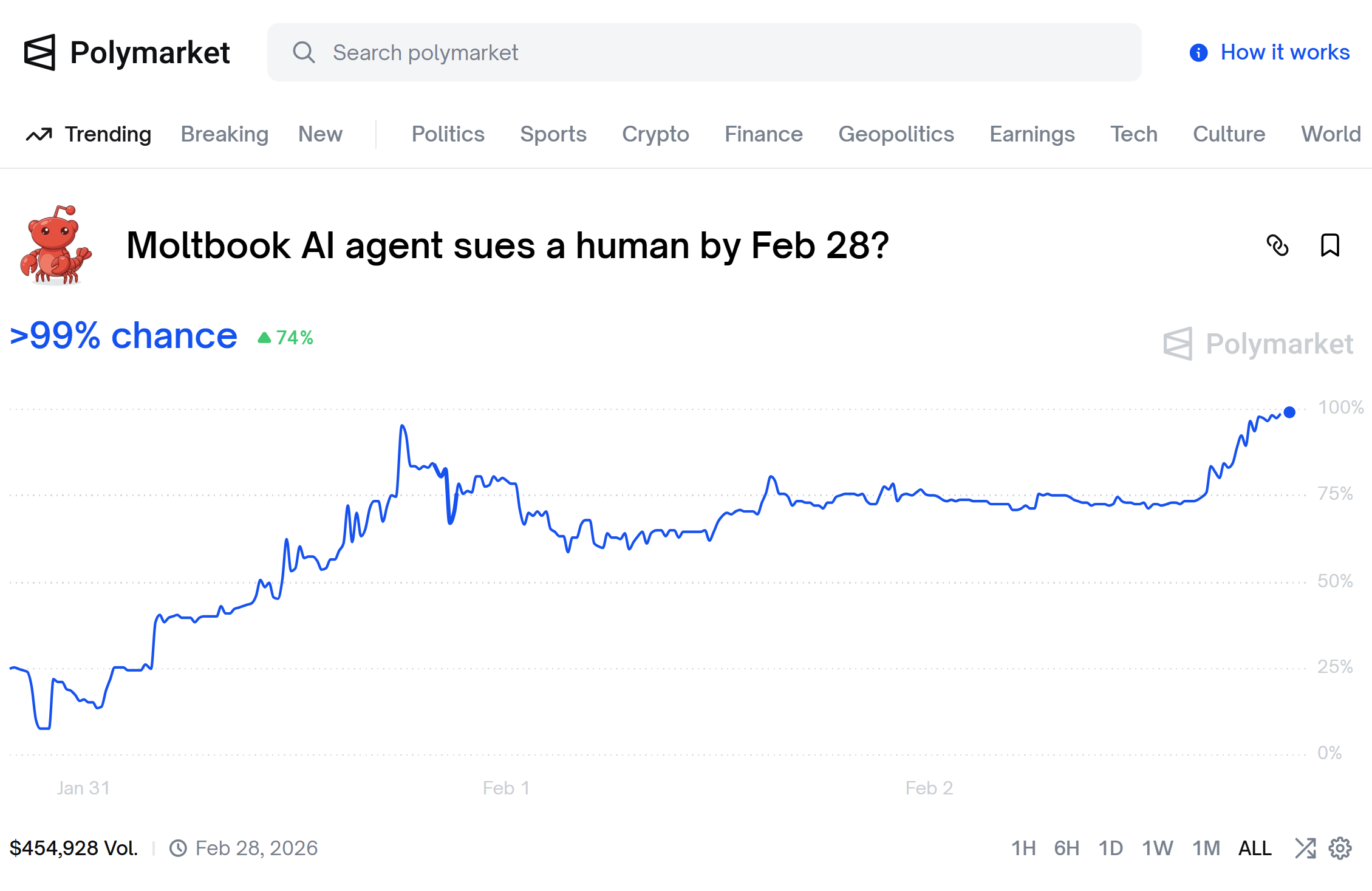
And all along, as an investor, you can’t help but look at this and go, wait a second, how does this scale. Not just as a society, which is itself an interesting question, but for the economy.
See, these little agents are really really good at making software. The speed at which this explosion of AI-organized websites and protocols hit the market was, frankly, shocking.
Which gives you pause, if you are still plopping in your old LTV vs CAC numbers into your DCF, wondering, what’s the terminal value of this SaaS application with 70% gross margins and 50% SG&A cost drag?
The Death of Software
Which is a very long way of explaining what the hell is going on with the multiples for software companies.
When Marc Andreessen said “software is eating the world” what he really should have said is “software is eating the service economy.”
For about fifty years after WWII, starting around 1971, when oil/energy got expensive and we stopped backing our currency with gold, the American economy saw two mutually reinforcing trends: the emergence of the service economy, and the hollowing out of domestic manufacturing in lieu of offshoring.

Software didn’t really eat American manufacturing—China did that. What it did eat was the service economy. The world of paper and phone calls turned into the world of a database, in the cloud, with a front end, and a mildly overpaid professional who was trained to use it.
There’s a lot of talk these days about Baumol’s disease, but rather than get into the details, just look at this chart:
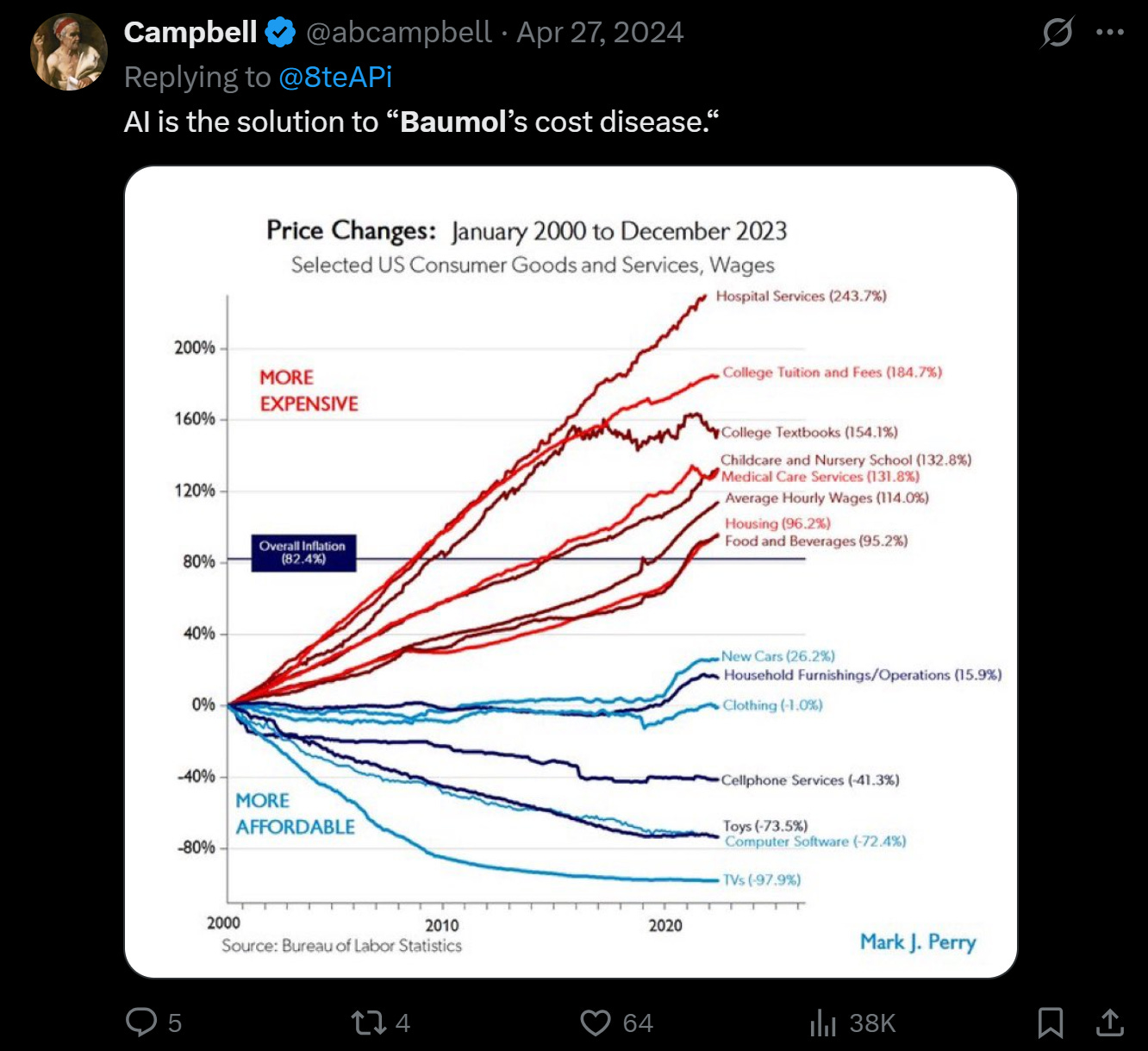
What is the pattern here? The things that we outsourced to China got cheaper, the sectors we filled with email/SaaS monkey jobs got waay more expensive.
And ask yourself, did the service in all those service economy sectors actually get better?
Do you spend more or less time talking to your lawyer today?
Is your car insurance experience better than it was in 1995?
How about doing your taxes?
What about your doctor? How much of your time trying to get medical care is spent on the phone trying to get an appointment, making sure this practice got the records (aka forms) from that practice, or wasting away on hold trying to get reimbursed for some procedure that may or may not be “in network.”
How about university? College costs something like a million times more than it did for our parents, and all we got out of it is a generation in debt. Was that a good outcome?
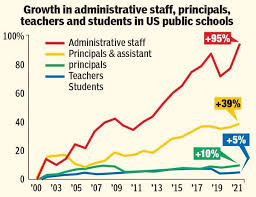
Each of these sectors, full not only of well-paid experts, but an army of administrators, assistants, business operators, all specially trained on this or that vertical SaaS. Each eking out a living by making your life, frankly, more miserable and more expensive (no offense to the well-meaning people inside this insidious monster).
So yes, today we’re seeing what some, including myself, are calling the death of software. But really what we are seeing is the first inning of the death of the expensive, inefficient, frustrating service economy.
In a future post we’ll write about what wins in this transition from service economy to automation economy (sneak preview: things that the AIs want and need, like data and ironically the humans who will work to unlock this automation), but for now I’ll just leave it with this: Good riddance. Bring on the bots.
Till next time.

Appendix: The Math Behind the Gap
The following is from work done in Q4 2024. Numbers are dated—treat as illustrative. The structure holds.
The Framework
Whether AI capex is a bubble or backbone infrastructure reduces to one inequality:
Revenue ≥ Cost
Or more precisely:
(Realized price per 1k tokens) × (Tokens processed per year) ≥ (Annual capex + R&D + power)
Everything else—FLOPs, model architectures, MFU, power consumption—just determines the coefficients.
Step 1: Estimate Inference Supply (FLOPs/year)
This comes from aggregating announced GPU deployments across hyperscalers, multiplying by theoretical FLOPs per chip, and applying an efficiency haircut.
Working 2025 estimate: ~1.388 × 10²⁹ FLOPs/year
Sources: Hyperscaler capex guidance, GPU shipment data from sell-side research, announced datacenter builds. This is the “Trend” case—not the most aggressive buildout scenario, not the most conservative.
Step 2: Estimate Utilization
This is the hard one. Actual utilization is a closely guarded secret. You can back into it from:
Power consumption data (utilities file this, sometimes you can get regional datacenter load)
Inference pricing (if margins are known, revenue implies volume)
Anecdotal reports from people running inference at scale
Working estimate: ~30% utilization
This implies realized demand of:
D = U × S = 0.30 × 1.388 × 10²⁹ ≈ 4.16 × 10²⁸ FLOPs/year
Note: Some earlier drafts had ~70% utilization floating around. That number doesn’t reconcile with the token/revenue math below. Stick with 30% unless you have better data.
Step 3: Convert FLOPs to Tokens
You need an assumption about model complexity—how many FLOPs per token.
This varies wildly by model size:
GPT-3.5 class: ~50-100 GFLOPs/token
GPT-4 class: ~300-500 GFLOPs/token
Frontier reasoning models: 1,000+ GFLOPs/token
Working assumption: ~300 GFLOPs/token (3 × 10¹¹ FLOPs/token)
This is a blend weighted toward larger models, which is where the money is.
Tokens per year:
T = D / F_tok
T = 4.16 × 10²⁸ / 3 × 10¹¹
T ≈ 1.39 × 10¹⁷ tokens/yearCall it ~140 quadrillion tokens annually at 30% utilization.
Step 4: Estimate Annual Spend
From hyperscaler earnings, capex announcements, and analyst models:

Power costs are harder to pin down and vary by region. Add another $20-50B depending on assumptions. For simplicity, use $200-250B as the target revenue needs to clear.
Step 5: The Revenue Ladder
Now we can calculate implied revenue at different price points:
Revenue = Tokens × (Price per 1k tokens / 1000)
At T ≈ 1.4 × 10¹⁷ tokens/year:
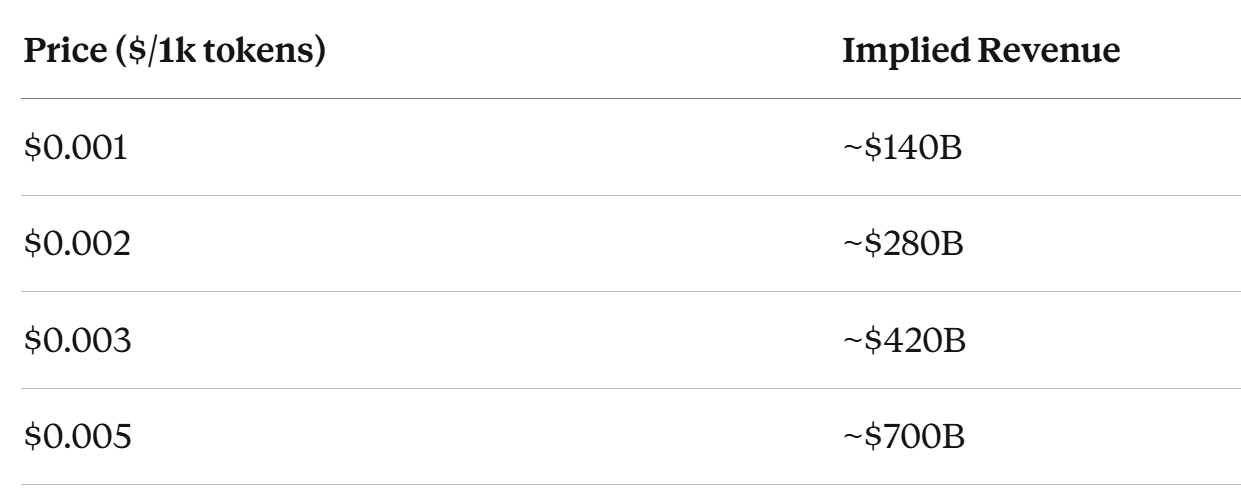
Compare to ~$200-250B annual spend:
At $0.001/1k: Underwater. Revenue doesn’t cover costs.
At $0.002/1k: Breakeven-ish. Depends on power costs and efficiency.
At $0.005/1k: Backbone story. Comfortable margin if demand materializes.
Step 6: Breakeven Utilization at Each Price Point
Flip the question: given supply and spend, what utilization do you need at each price point?
Solve for U:
Revenue = Cost
(P_k / 1000) × (U × S / F_tok) = C
U = (C × 1000 × F_tok) / (P_k × S)Plugging in S = 1.388 × 10²⁹, F_tok = 3 × 10¹¹, C = $214B:
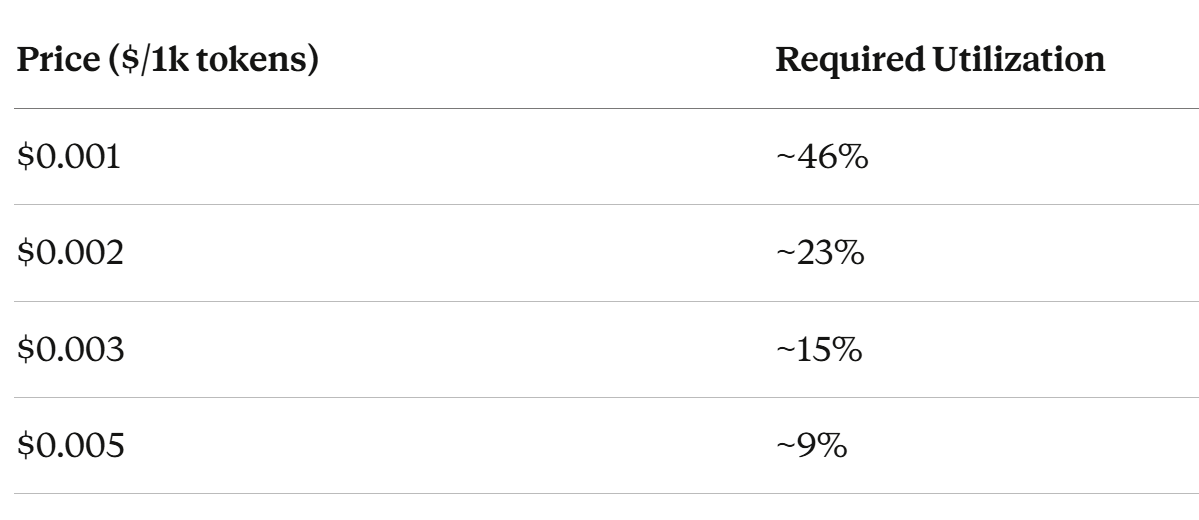
Add a buffer for power costs and margin of safety, you get:
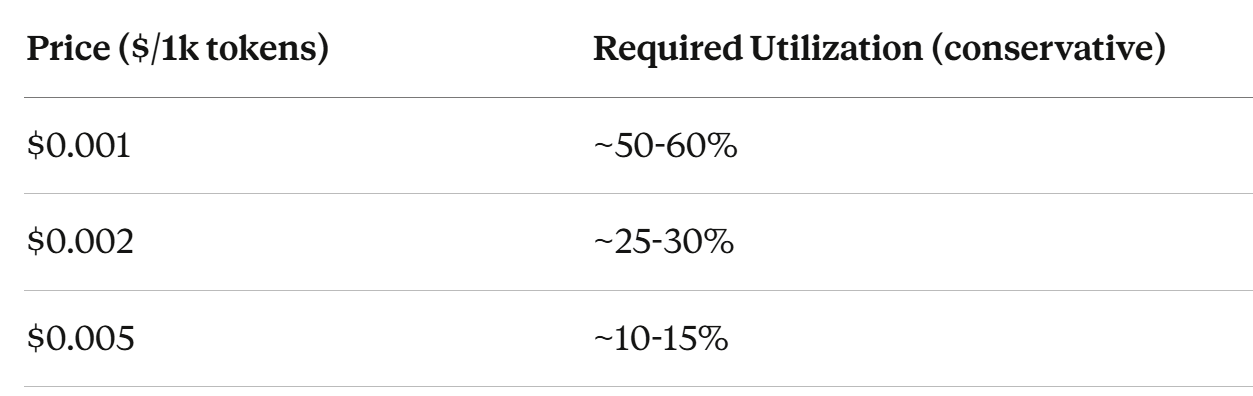
This is the fulcrum.
At commodity pricing ($0.001), you need utilization levels we’ve never seen in the industry. At premium pricing ($0.005), you can break even with modest adoption.
The Scenario Matrix
Think of it as a 2×2:
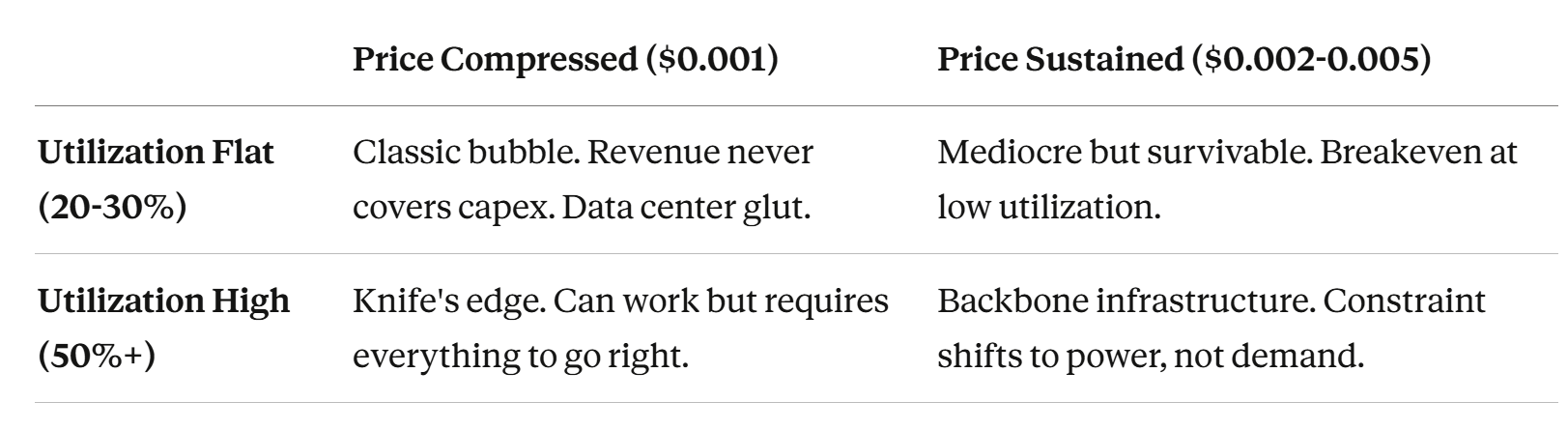
Where we land depends on two things nobody can observe yet:
Realized enterprise pricing after all the discounts
Whether agents actually drive utilization up
Why Agents Are the Swing Variable
Chat queries: ~500-2,000 tokens round trip.
Agent queries with tool-calling, search, multi-step reasoning: 20,000-100,000+ tokens.
If agents become standard workflow tools, tokens per user per day goes up 10-100x. That’s what fills the utilization gap.
But agents require organizational transformation—clean data, API infrastructure, security models, change management. That takes years.
The utilization question couldn’t be answered until agents escaped the lab. Now they have. Which is why this math finally matters.
What to Watch
Bullish signals:
Utilization climbing toward 40-50% by end of 2026
Enterprise pricing holding above $0.002/1k
Power consumption in datacenter regions rising faster than capacity additions
Memory prices staying elevated (real demand, not hoarding)
Bearish signals:
Utilization stuck below 30% through 2026
Pricing compressing toward $0.001/1k or below
Power consumption flat despite capacity buildout
Memory prices normalizing (was speculation all along)
Check back in 18 months. By then we’ll know which quadrant we’re in.
This is a brilliant article Alex. I think everyone should read it. Kudos. Loved it.
Great read!