

Bloomberg enters the AI game

This week, Bloomberg entered the AI game.
Welcome to the party boys.
I know this, because approximately half of you forwarded me the release announcement.
On the one hand they have managed to generate significant buzz, as there is an army of miserable financial services workers who would currently like better interfaces for dealing with computing.
On the other, we think they miss a big part of the value that financial knowledge workers need to get the most from the advances in AI.


In looking into the actual paper, we found something remarkably strange. Something none of the people who forwarded the news to us seemed to have noticed.
For all the talk about using GPT on financial data, the model in question…doesn’t really deal with financial data!
What do I mean by this?
Well, if you actually look at the training data, you see something kind of odd.
Whether you are talking about “Documents”
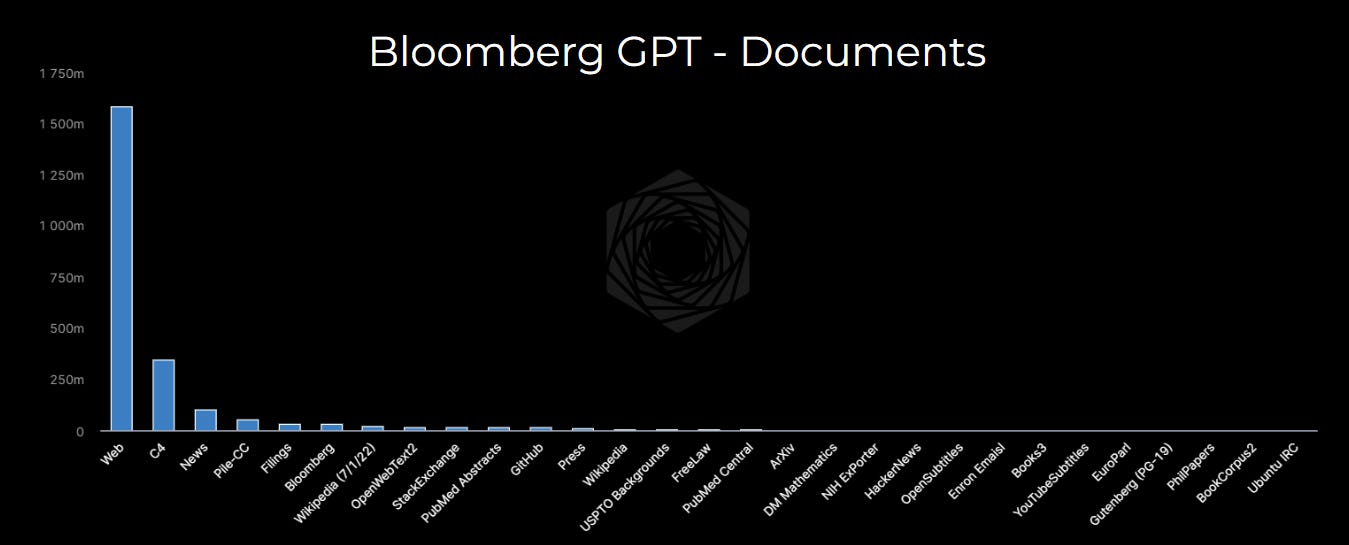
Or “Tokens” (aka computer readable chunks of words)
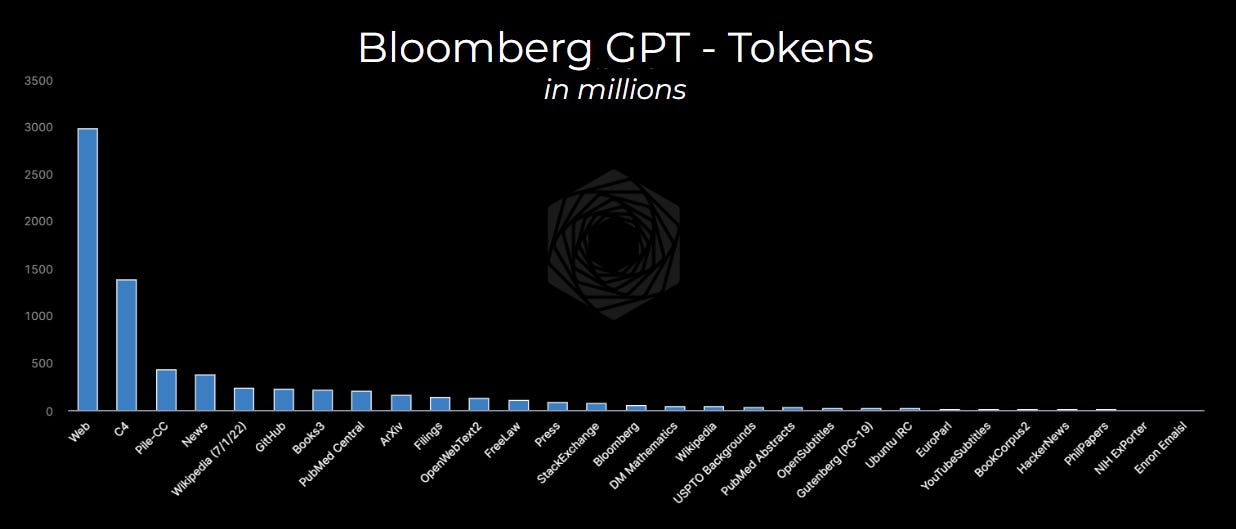
Or heck, even “Characters,” the results are pretty clear.
Much like many other popular Large Language Models, Bloomberg trains on ‘words’ and ‘tokens’ and NOT individual time series or tables. In fact, the vast majority if it similar to other training models which scrape cleaned up versions of web / public data (with some Bloomberg NEWS articles thrown in for help with the domain.

Why does this matter? Well, when you train your model on just text, you get some predictable problems.
These problems relate to the reason why both JP Morgan and Italy have now banned ChatGPT.

Financial knowledge workers need answers to questions which have the following features:
Up to date
Which is impossible with models that rely on cached versions of the web).
Accurate
Which is difficult when the model is ‘gleaning’ the answer, vs actually finding a relevant source.
Auditable
No answer in finance is taken for granted, it must be something a boss, client, investor or regulator can probe and recreate.
Reliable
Most financial data need a LOT of cleaning before it can be used in algorithms or presentations. Analysts spend years cleaning and torturing data from different data based to triangulate truth and build custom investment logic into their primary data.
GPT based models have none of these.
Why does this matter?
Well, most financial folks don’t need quick but messy answers to questions based on looking through millions of text documents. They need need help with, finding, cleaning, analyzing and manipulating DATA.

This becomes more obvious when you look at the actual ‘tests’ they use to validate and justify the quality of their model.





So, instead of movie recommendations, sentiment analysis and understanding of sports, financial knowledge workers need help finding, cleaning, analyzing and visualizing data.
Kind of like Rose.